
Couchbase with Windows and .NET – Part 2 – Lingo
This blog post is part 2 of a series. Part 1 covered how to install and setup Couchbase on Windows.
In part 1 – Setup, I showed the very basics of how to get Couchbase Server up and running. If you’re like me, you’re itching to get into some code and see what you can do. But before we go there, I want to go over some of the lingo with Couchbase. It’s not a difficult tool to use, but it is different from the RDBMS systems like SQL Server that you’re probably used to. So, this blog post series is as much for you as it is for me: I’m learning as I go.
Here is the short version from a developer’s point of view: A Couchbase cluster contains nodes. Nodes contain buckets. Buckets contain documents. Documents can be retrieved multiple ways: by their keys, queried with N1QL, and also by using Views (which use map/reduce). (With Couchbase 4.5, parts of documents can be updated with the subdocument API). Now let’s look at each element in further detail.
Cluster
To start with, let’s talk about a “cluster.” One of Couchbase’s strengths is its ability to scale out: drop in additional servers to handle more data efficiently. This is in contrast to scaling up: which is to replace a server with a beefier, faster server (which you can also do with Couchbase). A cluster is a collection of related nodes that coordinate with each other and sort of act as one logical server. When using Couchbase, you’re always dealing with a cluster, even if you only have one node in that cluster. “Couch” is an acronym of “Cluster Of Unreliable Commodity Hardware.”
Node
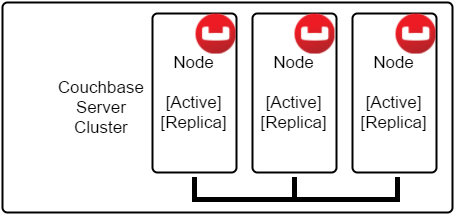
A node is a single component in a cluster. This usually corresponds to one server. When you define a cluster, you define a RAM quota (per each service). This is the amount of RAM that each node in the cluster will use to provide a given service. So if the Data RAM quota is 2gb, then each node in the cluster that provides a data service will have 2gb of RAM to work with. Each node also contributes disk space to the cluster.
A node provides one or more services: data storage, indexing, querying, and full text search. You can configure your cluster however you’d like: one node that provides all services up to one node for each type of service, and you can then scale out and/or scale up. (Example: I could add 5 more nodes for data storage, 1 more node for indexing, and I’ll use a single really beefy server for querying).
Nodes also store replica data from other nodes. That way, if another node goes down, the replica data can be ‘promoted’ to active, and your application can go on its merry way.
From the perspective of writing code, this behavior should all be transparent. The configuration of nodes in a cluster can (and will) change, but the code doesn’t have to.
Bucket
A bucket is a place to store documents. Each document has a key. Within a bucket, each key must be unique. The documents within a bucket do not have to be similar at all. You could store a document that contains information about a user, and a document with information about a building. You can configure multiple buckets on a node, but it’s recommended that you stick to 10 buckets or fewer. To use a relational database analogy, a bucket is more like a database instance or catalog. It’s not like a table.
The reason that Couchbase is so fast is because each bucket stores a lot of its documents in RAM. When a request comes in for a document, the document (or at least the document’s meta-data) will likely already be in RAM, ready to go–no disk access required. When a new or updated document comes in, it’s updated in RAM and then put on a queue to write it to disk and to replicate it to other nodes. When memory needs to be freed for other documents, the meta-data stays in RAM for later retrieval: only the value is ejected (unless you configure the bucket otherwise).
Document
In a very basic sense, a Couchbase bucket is just a giant Dictionary<string,string>. You can use whatever you want for the key (as long as it’s unique), and you can put whatever you want in the value. However, if you decide to store JSON in the value, then you also get additional functionality: structure, indexing, N1QL, views, etc. So while it’s possible and supported to use non-JSON values, typically most values will be stored as JSON. This is why Couchbase is called a “document database”. Each bucket contains documents, which are a value and associated metadata (like the key).
So, in English, it would makes sense to say things like:
- “Hey Couchbase cluster X, in bucket ‘foo’, please give me the value of the document with the key ‘bar'”
- “Hey Couchbase cluster X, in bucket ‘foo’, here’s a new document with value ‘baz’, it has a key of ‘qux’
- “Hey Couchbase cluster X, in bucket ‘foo’, please change the value of the document with key ‘corge’ to have a value of ‘grault’
N1QL
Couchbase recognizes that relational databases have been a huge part of many developer’s careers. Many developers feel comfortable writing SQL. However, document databases don’t really work the same way as relational databases, so often they have to learn a whole new way of doing things. With Couchbase Server, however, if you are using JSON documents, you can write queries in a language called N1QL (N1QL stands for “Non-first Normal Form Query Language, and is pronounced “nickel”). N1QL is a superset of SQL. This means that, basically, if you know SQL, then you know N1QL. There are a few differences and some extra keywords, but here’s an example just to show you how similar they are:
|
1 2 3 4 |
SELECT name, author FROM `books-bucket` WHERE YEAR(published) >= 1998 |
That will return something like:
|
1 2 3 4 5 6 7 |
{ "results": [ { "name" : "The Little Book of Calm", "author" : "Manny Bianco" }, { "name" : "AOP in .NET", "author" : "Matthew D. Groves" } ] } |
As I’ll show you in later blog posts, the Linq2Couchbase library leverages N1QL to give you a Linq provider that will feel very similar to Entity Framework, NHibernate.Linq, or other Linq providers that you’re used to.
Indexes
Indexes in Couchbase are just as important as in relational databases. Probably more so, because of the volume of data that Couchbase can handle as it scales out.
To enable N1QL queries on a bucket, at the very least you need to create a primary index. This is an index on the bucket itself. Here’s how to create one with N1QL: CREATE PRIMARY INDEX ON my-bucket;
If you’re using JSON documents, then you can create indexes based on the fields in JSON documents. For instance, if you have a lot of documents that have “name” or “author”, and you will often be querying based on these fields, you can create indexes for them. These are called “secondary indexes.”
Conclusion
I’m as anxious to dive into code as you are, but it’s good to have this lingo down first. I’ve tried to focus on the most important concepts at the expense of some of the details. So, if you have questions, please leave a comment below, contact me on twitter, or email me via matthew.groves AT couchbase DOT com. I’d love to hear from you.