
One of the biggest barriers for anyone who wants to start using new technologies is usually the learning curve. Often while starting a new project, we end up choosing to use what we already know to avoid any friction right at the beginning.
I have spent most of my career working as a Java developer, and in the last few years I fell in love with the JPA + Spring-Boot + Lombok + Spring Data combination, but the one thing that still annoyed me was mapping relationships.
JPA is known for loading unnecessary data from the database, and over time you are forced to revisit some of your entities to change a few relationships from EAGER to LAZY. It can significantly improve your performance as you will avoid a lot of unnecessary JOINS but it does not come for free. You will be required to do a lot of refactoring to load those new lazy objects whenever they are required.
This common pattern always bothered me and I was really happy when I found that Spring Data and Couchbase can connect (full doc here). It is simply the best part of two worlds, I can program like I would in a relational database but still leveraging all the speed of Couchbase and the power of N1QL. Let’s see how to set up a simple project.
Setting-Up Spring Data, Spring Boot, and Couchbase
Prerequisites:
- I will assume that you already have Couchbase installed, if you don’t, please download it here
- I am also using Lombok, so you might need to install Lombok’s plugin on your IDE: Eclipse and IntelliJ IDEA
First, you can clone my project:
|
1 |
git clone https://github.com/deniswsrosa/couchbase-spring-data-sample.git |
or simply go to Spring-Boot Initialzr and add Couchbase and Lombok as dependencies:
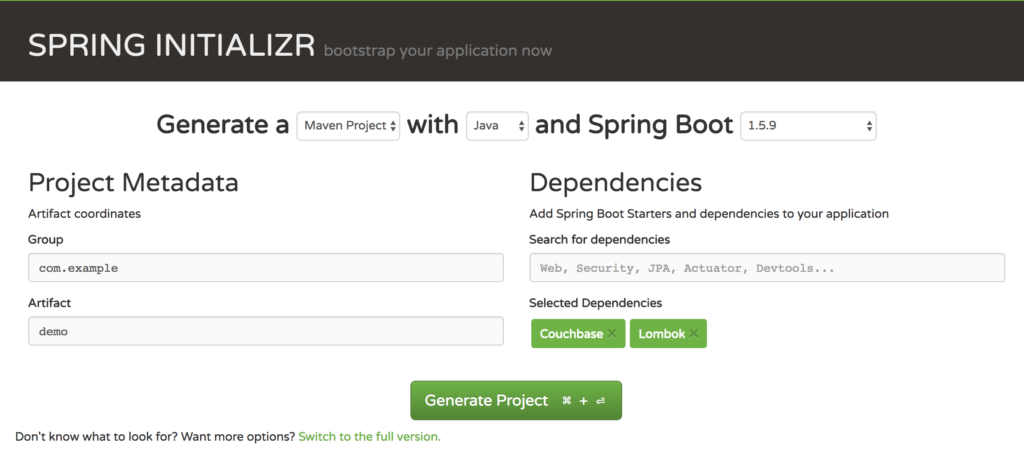
Note: Lombok is not a required dependency, but it helps to significantly reduce your code base.
Now, let’s define your bucket configuration in the application.properties file:
|
1 2 3 4 |
spring.couchbase.bootstrap-hosts=localhost spring.couchbase.bucket.name=test spring.couchbase.bucket.password=couchbase spring.data.couchbase.auto-index=true |
And that’s it! You are already able to start up your project using:
|
1 |
mvn spring-boot:run |
Mapping an Entity
So far, our project does not do anything. Let’s create and map our first entity:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
@Document @Data @AllArgsConstructor @NoArgsConstructor @EqualsAndHashCode public class Building { @NotNull @Id private String id; @NotNull @Field private String name; @NotNull @Field private String companyId; @Field private List<Area> areas = new ArrayList<>(); @Field private List<String> phoneNumbers = new ArrayList<>(); } |
-
- @Document: Couchbase’s annotation which defines an entity, similar to @Entity in JPA. Couchbase will automatically add a property called _class in the document to use it as the document type.
- @Data: Lombok’s annotation, auto-generate getters and setters
- @AllArgsConstructor: Lombok’s annotation, auto-generate a constructor using all fields of the class, this constructor is used in our tests.
- @NoArgsConstructor: Lombok’s annotation, auto-generate a constructor with no args (required by Spring Data)
- @EqualsAndHashCode: Lombok’s annotation, auto-generate equals and hashcode methods, also used in our tests.
- @NotNull: Yes! You can use javax.validation with Couchbase.
- @Id: The document’s key
- @Field: Couchbase’s annotations, similar to @Column
Mapping entities in Couchbase is really simple and straightforward, the biggest difference here is the @Field entity which is used in 3 different ways:
- Simple property: In cases like id, name and companyId, the @Field acts pretty much like the @Column in JPA. It will result in a simple property in the document:
|
1 2 3 4 5 |
{ "id": "building::1", "name": "Couchbase's Building", "companyId": "company::1" } |
- Arrays: In the phoneNumbers’s case it will result in an array inside the document:
|
1 2 3 |
{ "phoneNumbers": ["phoneNumber1", "phoneNumber2"] } |
- Entities: Finally, in the areas’s case, @Field acts like a @ManyToOne relationship, the main difference is that you are not required to map anything in the Area entity:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
@EqualsAndHashCode @AllArgsConstructor @NoArgsConstructor @Data public class Area { private String id; private String name; private List<Area> areas = new ArrayList<>(); } |
Repositories
Your repositories will look very similar to standard Spring Data repositories but with a few extra annotations:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
@N1qlPrimaryIndexed @ViewIndexed(designDoc = "building") public interface BuildingRepository extends CouchbasePagingAndSortingRepository<Building, String> { List<Building> findByCompanyId(String companyId); Page<Building> findByCompanyIdAndNameLikeOrderByName(String companyId, String name, Pageable pageable); @Query("#{#n1ql.selectEntity} where #{#n1ql.filter} and companyId = $1 and $2 within #{#n1ql.bucket}") Building findByCompanyAndAreaId(String companyId, String areaId); @Query("#{#n1ql.selectEntity} where #{#n1ql.filter} AND ANY phone IN phoneNumbers SATISFIES phone = $1 END") List<Building> findByPhoneNumber(String telephoneNumber); @Query("SELECT COUNT(*) AS count FROM #{#n1ql.bucket} WHERE #{#n1ql.filter} and companyId = $1") Long countBuildings(String companyId); } |
- @N1qlPrimaryIndexed: This annotation makes sure that the bucket associated with the current repository will have a N1QL primary index
- @ViewIndexed: This annotation lets you define the name of the design document and View name as well as a custom map and reduce function.
In the repository above, we are extending CouchbasePagingAndSortingRepository, which allows you to paginate your queries by simply adding a Pageable param at the end of your method definition
As it is essentially a repository, you can leverage all Spring Data keywords like FindBy, Between, IsGreaterThan, Like, Exists, etc. So, you can start using Couchbase with almost no previous knowledge and still be very productive.
As you might have noticed, you can create full N1QL queries but with a few syntax-sugars:
- #(#n1ql.bucket): Use this syntax avoids hard-coding your bucket name in your query
- #{#n1ql.selectEntity}: syntax-sugar to SELECT * FROM #(#n1ql.bucket):
- #{#n1ql.filter}: syntax-sugar to filter the document by type, technically it means class = ‘myPackage.MyClassName’ (_class is the attribute automatically added in the document to define its type when you are working with Couchbase on Spring Data )
- #{#n1ql.fields} will be replaced by the list of fields (eg. for a SELECT clause) necessary to reconstruct the entity.
- #{#n1ql.delete} will be replaced by the delete from statement.
- #{#n1ql.returning} will be replaced by the returning clause needed for reconstructing the entity.
To demonstrate some of the cool capabilities of N1QL, let’s go a little deeper in two methods of our repository: findByPhoneNumber and findByCompanyAndAreaId:
findByPhoneNumber
|
1 2 |
@Query("#{#n1ql.selectEntity} where #{#n1ql.filter} AND ANY phone IN phoneNumbers SATISFIES phone = $1 END") List<Building> findByPhoneNumber(String telephoneNumber); |
In the case above we are simply searching for buildings by telephone numbers. In a relational world, you would normally need 2 tables to accomplish nearly the same thing. With Couchbase we can store everything in a single document, which makes loading a “building” much faster than what you would get using any RDBMS.
Additionally, you can speed up your query performance even more by adding an index on the phoneNumbers attribute.
findByCompanyAndAreaId
|
1 2 |
@Query("#{#n1ql.selectEntity} where #{#n1ql.filter} and companyId = $1 and $2 within #{#n1ql.bucket}") Building findByCompanyAndAreaId(String companyId, String areaId); |
In the query above we are basically trying to find the root node (Building) giving a random child node (Area). Our data is structured as a tree because an Area could also have a list of other areas:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
@EqualsAndHashCode @AllArgsConstructor @NoArgsConstructor @Data public class Area { private String id; private String name; private List<Area> areas = new ArrayList<>(); } |
This type of querying is one of the most expensive and complex operations when you are working with a relational database, in most of the cases you either find the root node by hand or by using some big fat query with UNIONs and CONNECTED BYs.
Here you can solve this problem by using a magical keyword called WITHIN.
Services
By default, you will inject and use your repositories in your Services like you normally would, but you can additionally access Couchbase’s specific repositories capabilities using the method getCouchbaseOperations()
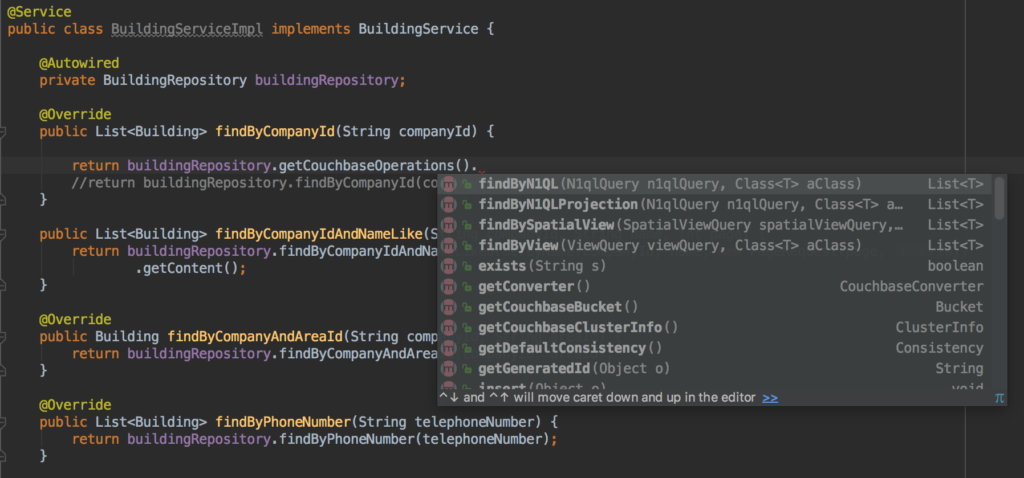
Everything in Action
Using services are to exactly what you would expect:
|
1 |
buildingService.findById("building::1") |
|
1 2 3 4 |
Building bulding = new Building("bulding::1", "Couchbase Building", "company::1", new ArrayList<>(), new ArrayList<>()); buildingService.save(building); |
|
1 |
buildingService.findByCompanyIdAndNameLike("company::1", "Cou%", 0); |
Check out the integration test class BuildingServiceIntegrationTest to see everything in action.
If you have any questions, tweet me at @deniswsrosa or ask a question on our forum
This is a great blog! I am pretty new to Spring and Spring boot . And we are setting up CouchBase . I have the CouchBase running locally in my computer, However did not find any provision for giving password for the bucket. And hence when I am running my application its giving me InvalidPasswordException: Passwords for bucket do not match.
Could you please let me know how do I resolve this
Hi Kn,
The easiest way is to create a user with the same name as your bucket, and then you can follow this tutorial
https://www.couchbase.com/couchbase-spring-boot-spring-data/
If you want to have multiple users accessing the same bucket, you will need to implement the AbstractCouchbaseConfiguration class
https://stackoverflow.com/questions/53177777/couchbase-6-0-springboot-invalidpasswordexception
I am pretty new to Couchbase and spring data ,Spring boot implementation. I am using document subdocument API to update,Insert and remove the subdocument without reading the whole document. I can code the path to subdocument and do mutation operations directly on the subdocument. One of the advantage with document subdocument API is I can act on subdocument without locking the whole document(In my use case).
How can I achieve the same using spring-data and Spring boot . I see the major difference where spring-data works with N1QL query and POJO where as document subdocument API work with Json.
Reference to document Subdocument API: https://docs.couchbase.com/java-sdk/2.7/subdocument-operations.html
Hi Muraic,
Subdocuments are usually faster, as you are get the document by its key. However, Spring data is much more productive.
You can use spring data and still be able to make subdocument operations, if you call yourRepository.getCouchbaseOperations().getCouchbaseBucket() you will get access to the Bucket object, which potentially is the one you are using right now.
Is it possible to connect via SSL and use field encryption with Spring Data Couchbase?
Hi Denis, I am very – very new to open system technologies and I am trying to understand how your project executes. I have installed couchbase and created one document and able to see running server in console.
However, I wanted to see how Java will integrate with couchbase, so imported your project and doing mvn clean install, but getting authentication errors like :
2019-05-21 20:14:31.776 WARN 9672 — [ cb-io-17-3] c.c.client.core.endpoint.Endpoint : [null][KeyValueEndpoint]: Authentication Failure.
2019-05-21 20:14:31.777 WARN 9672 — [ cb-io-17-3] c.c.client.core.endpoint.Endpoint : Error during reconnect:
-05-21 20:14:31.778 WARN 9672 — [ cb-io-17-3] c.c.client.core.endpoint.Endpoint : [null][KeyValueEndpoint]: Could not connect to endpoint, retrying with delay 4096 MILLISECONDS:
2019-05-21 20:14:35.922 WARN 9672 — [ cb-io-19-1] c.c.client.core.endpoint.Endpoint : [null][KeyValueEndpoint]: Authentication Failure.
2019-05-21 20:14:36.020 WARN 9672 — [ cb-io-19-2] c.c.client.core.endpoint.Endpoint : [null][KeyValueEndpoint]: Authentication Failure.
2019-05-21 20:14:36.021 WARN 9672 — [ cb-io-19-2] c.c.client.core.endpoint.Endpoint : Error during reconnect:
2019-05-21 20:14:36.029 WARN 9672 — [ cb-io-19-3] c.c.client.core.endpoint.Endpoint : [null][KeyValueEndpoint]: Authentication Failure.
2019-05-21 20:14:36.030 WARN 9672 — [ cb-io-19-3] c.c.client.core.endpoint.Endpoint : Error during reconnect:
2019-05-21 20:14:36.362 WARN 9672 — [ cb-io-19-3] c.c.client.core.endpoint.Endpoint : [null][KeyValueEndpoint]: Authentication Failure.
2019-05-21 20:14:36.363 WARN 9672 — [ cb-io-19-3] c.c.client.core.endpoint.Endpoint : [null][KeyValueEndpoint]: Could not connect to endpoint, retrying with delay 32 MILLISECONDS:
could you please advise, if I am missing any steps. Do I have to do some setting with respect to bringing couchbase localhost server or I am missing couchbase dependencies / I don’t have any idea, please advise.
Hi Denis, I am very – very new to open system technologies and I am trying to understand how your project executes. I have installed couchbase and created one document and able to see running server in console.
However, I wanted to see how Java will integrate with couchbase, so imported your project and doing mvn clean install, but getting authentication errors like :
2019-05-21 20:14:31.776 WARN 9672 — [ cb-io-17-3] c.c.client.core.endpoint.Endpoint : [null][KeyValueEndpoint]: Authentication Failure.
2019-05-21 20:14:31.777 WARN 9672 — [ cb-io-17-3] c.c.client.core.endpoint.Endpoint : Error during reconnect:
could you please advise, if I am missing any steps. Do I have to do some setting with respect to bringing couchbase localhost server or I am missing couchbase dependencies / I don’t have any idea, please advise.
never, mind, I found the solution :) but will have more doubts in coming days…
Post your questions on StackOverflow, I can answer it there.
Hi Rosa,
I am new in Couchbase with Spring data but based on the R&D i am able to to do CRUD operation easily. Still i am facing a issue of “key”:{“empty”: “false”} while storing List value.
You have also described above that :-
private List phoneNumbers = new ArrayList();
and,
Arrays: In the phoneNumbers’s case it will result in an array inside the document:
like this : –
{
“phoneNumbers”: [“phoneNumber1”, “phoneNumber2”]
}
But it always save as :- “key”:{“empty”: “false”}.
> But it always save as :- “key”:{“empty”: “false”}.
This issued is fixed in spring-data-couchbase 4.0.2
Regards