
High Performance with Couchbase Server on Google Cloud
Couchbase Server is an open source, multi-model NoSQL distributed database that incorporates a JSON document database and key-value store. Couchbase Server is built on a memory-centric architecture designed to deliver consistent high performance, availability, and scalability for enterprise web, mobile, and Internet of Things applications. Couchbase Server also does very well on Google Compute Engine, offering superior price/performance. Google posted a set of results on Google Cloud blog post here and in this post I’d like to take you through the full set of test runs we have done on the platform.
Over the last year, technology partners have been reporting some exciting performance stats on Google Compute Engine, with Cassandra able to sustain 1 million writes per second. We took that as a challenge, and decided to see how much further we could push the scale, and drive down price/performance. This paper details the results from our experimentations.
Before I dive in, I want to thank David Haikney (Couchbase) and Dave Rigby (Couchbase) for all work they have done on the benchmark measurements and Ivan Santa Maria Filho (Google) for all the guidance he provided.
Summary
Couchbase Server was able to sustain 1.1 million writes per second. The data set size was 3 billion items with a value size of 200 bytes. Pure write workloads are not the only type of workload that is interesting in database but is a challenging one. Number of customers developing IoT (internet of things) applications are faced with a similar challenge. The results of the test prove that Couchbase Server on Google Cloud Platform can be a great fit for IoT apps writing data with high velocity at high volumes.
Benchmark Details
In our journey, we have tried 2 main benchmark configurations.
- Benchmark A: this benchmark configuration operated over 3B items. This measurement simulated the configuration published on Cassandra on Google Cloud.
- Benchmark B: This second measurement was done on a smaller data set of 100M items. This measurement simulated the configuration published by Aerospike on Google Cloud.
Before I plunge into more details, you can try these benchmarks out yourself, or simply look through the scripts for more details. Here is our github repo.
Benchmark A:
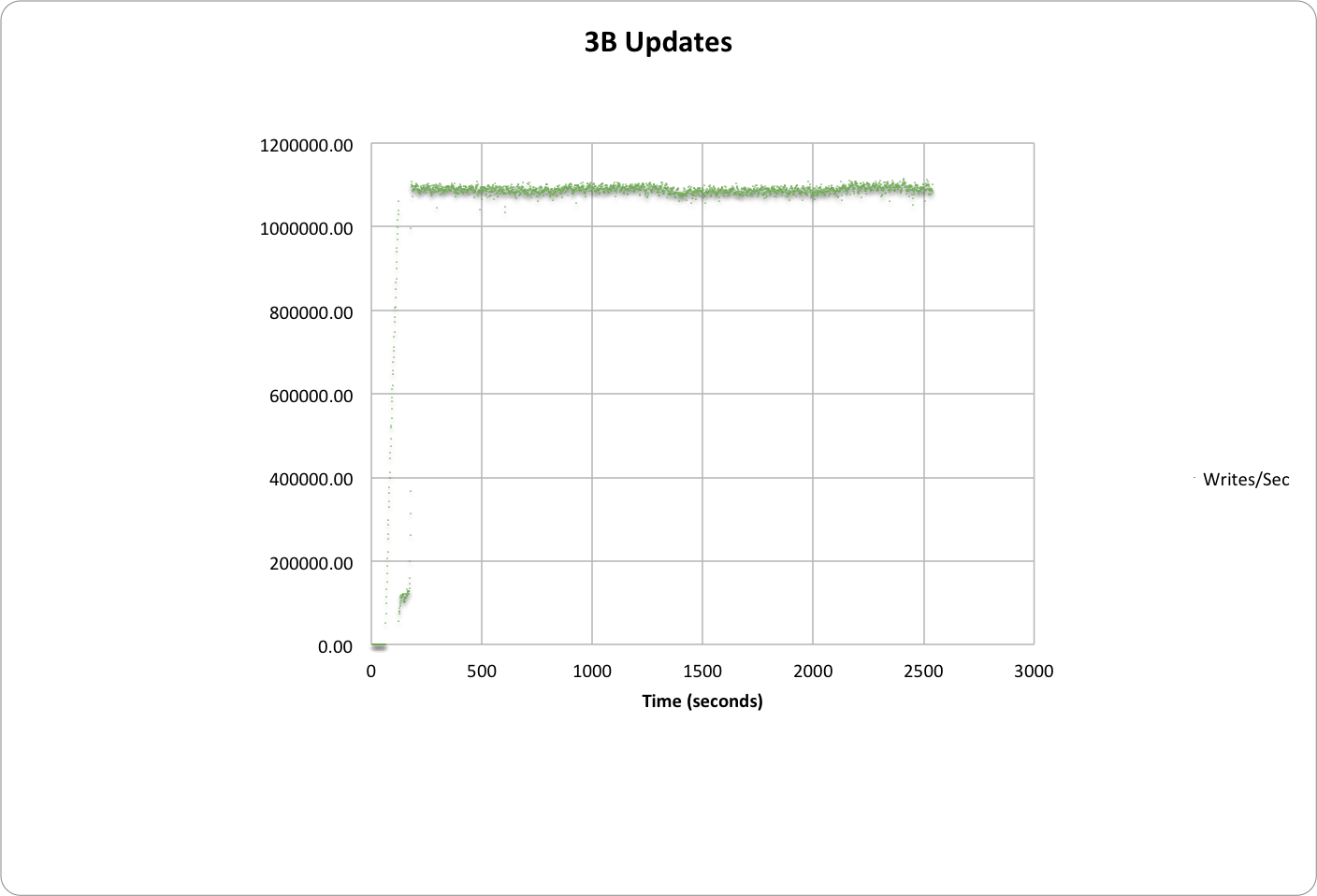
1.1M writes/sec over 3B Items with 50 nodes (n1-standard-16)
- 1.1M writes/sec with 3B total items
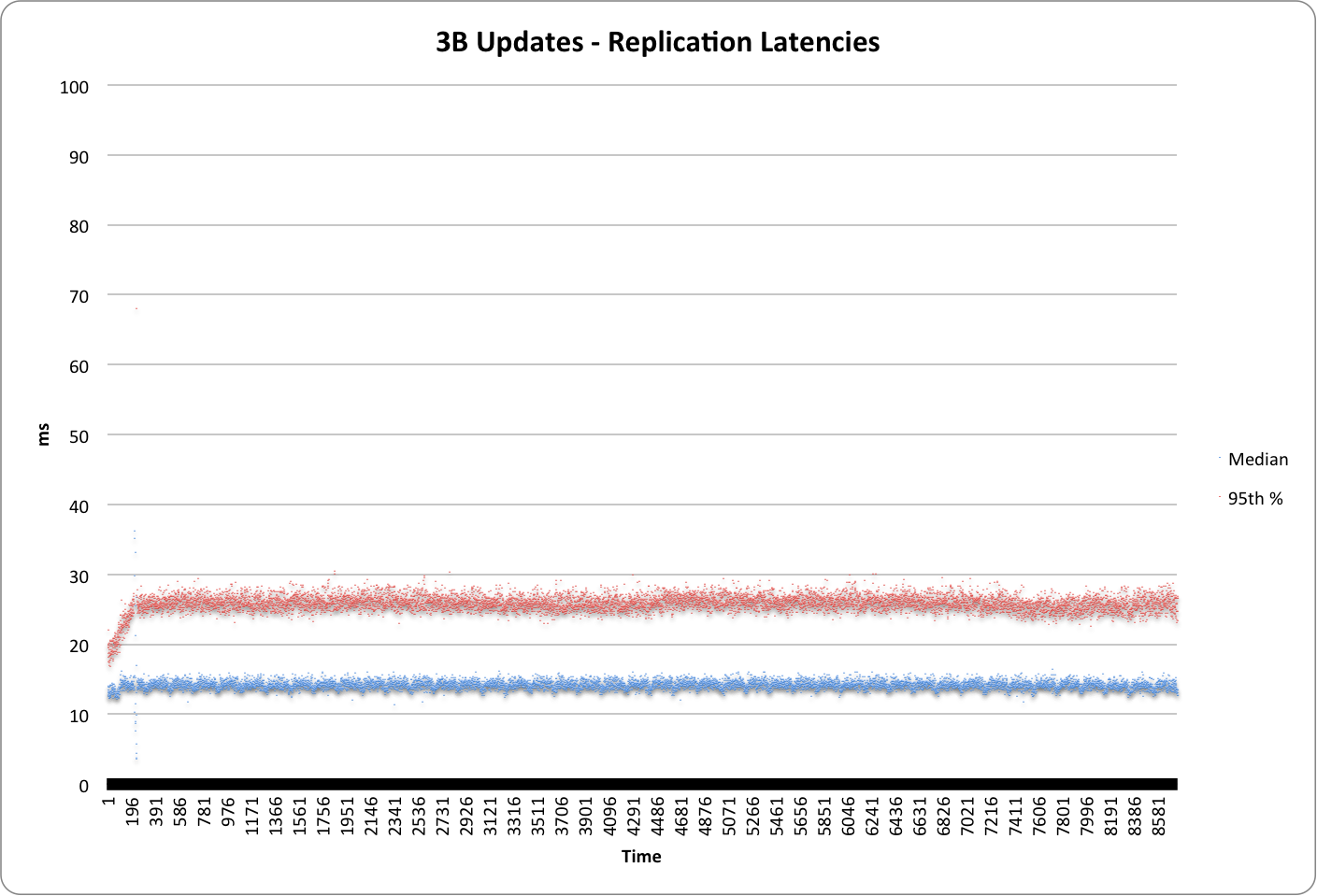
- Median latency was 15ms
- 95th% latency was 27ms.
- The total cost of running the benchmark for an hour is $56.3/hr.
Graph below shows the warmup and the sustained writes over time reaching 1.1M.
Graph below plots the median and 95% latency during the test run
Base Data-Set and Bucket Configuration
- Workload operated on 3 billion total items
- Each item has exactly 200 bytes value.
Couchbase Server Configuration:
- Debian was the OS of choice for this run (Debian Wheezy Backports).
- Cluster Configuration
- Server RAM Quota was set to 50GB
- Disk queue capacity was set to 5M items
- IO Threads were at 4 writer and 1 reader thread
- Bucket Configuration:
- All 3B items were configured to reside in a single bucket.
- 2 copies of the data was maintained on 2 separate nodes for redundancy. Bucket configuration specified 1 replica in addition to the master copy.
- Bucket eviction policy was set to “value eviction”
- Bucket RAM Quota was set to 50GB per node.
- Compaction was disabled
Virtual Machine Configuration
- VM Count: 50
- VM Size: n1-standard-16
There were many options to pick from on the VM sizes. However we have found the n1-standard-16 with 16 cores to be a great fit for optimal price performance. The test was run with 50, n1-standard-16 VM with a total of 60GB RAM on each node.
- Storage: 500GB SSD Persistent Disks
Google Cloud storage performed great under Couchbase Server. We used non-ephemeral, persisted storage option to make this a realistic deployment for production loads. The most optimal throughput with Couchbase Server was achieved with the SSD Persistent Disk offering. Couchbase Server used 500GB SSD Persistent Disk as the data volume. Couchbase Server did not use the 10GB root volume for database operations. Journaling was disabled (noatime) on data volume.
- Cost per Node: $1.12 / hr.
- Total Cost with 50 nodes: $56.30 / hr
Workload Properties and the Added Durability with “ReplicateTo” flag
The load was generated using pillowfight tool. To provide the added durability guarantee, pillowfight tool was modified to add the “ReplicateTo” flag to each write. The option ensures that writes are acknowledged only after the write operation reaches both copies of the data maintained by Couchbase Server.
Couchbase Server uses an active master replica for all of its writes and maintains secondary replicas for redundancy. Couchbase Server comes with a powerful built in replication technology named DCP (database change protocol). DCP streams changes to secondary replicas. Couchbase can maintain sub-millisecond latencies in its default write model with its efficient in memory cache. However the replicated write provides the firm durability under a node failure and ensure no data is lost in case of a failover.
Load Generation Configuration:
For load generation was done using 32 clients with n1-highcpu-8 VMs.
Following was the command line option used for the run 1 client instance with pillowfight
./cbc-pillowfight –min-size=200 –max-size=200 –num-threads=2 –num-items=93750000 –set-pct=100 –spec=couchbase://cb-server-1/charlie –batch-size=50 –num-cycles=468750000 –sequential –no-population –rate-limit=20000 –tokens=275 –durability
Benchmark B:
1M writes/sec over 100 million Items with 40 nodes (n1-standard-8)
- 1M writes/sec with 100M total items
- Median latency was 18ms
- 95th% latency was 36ms.
- The total cost of running the benchmark for an hour is $21.28/hr.
Base Data-Set and Bucket Configuration
- Workload operated on 100 million total items
- Each item has exactly 200 bytes value.
Couchbase Server Configuration:
- Debian was the OS of choice for this run (Debian Wheezy Backports).
- Cluster Configuration
- Server RAM Quota was set to 24GB
- Disk queue capacity was set to 5M items
- IO Threads were at 2 writer and 1 reader thread
- Bucket Configuration:
- All 100M items were configured to reside in a single bucket.
- 2 copies of the data was maintained on 2 separate nodes for redundancy. Bucket configuration specified 1 replica in addition to the master copy.
- Bucket eviction policy was set to “value eviction”
- Bucket RAM Quota was set to 24GB per node.
- Compaction was disabled
Virtual Machine Configuration
- VM Count: 40
- VM Size: n1-standard-8
For this smaller item count, we have found the n1-standard-8 with 8 cores to be the best fit for optimal price performance. The test was run with 40x n1-standard-8 VM with a total of 30GB RAM on each node.
- Storage: 500GB Standard Persistent Disk
Google Cloud storage performed great under Couchbase Server. We used non-ephemeral, persisted storage option to make this a realistic deployment for production loads. Optimal price/performance with Couchbase Server was achieved with the Standard Persistent Disk offering. Couchbase Server used 500GB Persistent Disk as the data volume. Couchbase Server did not use the 10GB root volume for database operations. Journaling was disabled (noatime) on data volume.
- Cost per node: $0.53 / hr.
- Total Cost with 40 nodes: $21.28 / hr
Workload Properties and the Added Durability with “ReplicateTo” flag
The load was generated using pillowfight tool. To provide the added durability guarantee, pillowfight tool was modified to add the “ReplicateTo” flag to each write. The option ensures that writes are acknowledged only after the write operation reaches both copies of the data maintained by Couchbase Server.
Couchbase Server uses an active master replica for all of its writes and maintains secondary replicas for redundancy. Couchbase Server comes with a powerful built in replication technology named DCP (database change protocol). DCP streams changes to secondary replicas. Couchbase can maintain sub-millisecond latencies in its default write model with its efficient in memory cache. However the replicated write provides the firm durability under a node failure and ensure no data is lost in case of a failover.
Load Generation Configuration:
For load generation was done using 32 clients with n1-highcpu-8 VMs.
Following was the command line option used for the run 1 client instance with pillowfight
./cbc-pillowfight –min-size=200 –max-size=200 –num-threads=2 –num-items=93750000 –set-pct=100 –spec=couchbase://cb-server-1/charlie –batch-size=50 –num-cycles=468750000 –sequential –no-population –rate-limit=20000 –tokens=275 –durability
Conclusion
1M writes/sec is an impressive amount of writes and many of you may never hit this kind of throughput in your systems but it is comforting to know that you can do this 1M writes/sec over 3B items in as few as 50 nodes in Google Cloud with 6x better price/performance compared to Cassandra with fully replicated writes!
Why on earth is compaction disabled?
If it\’s ON and start working it will be hard for it to catch up with the old database, which is filled up with 1m new documents per second, resulting in a duplication of the database.
It won\’t hurt in this case but i\’m guessing CPU is a big issue here in order to break the 1m barrier.
We did leave compaction out for the 2 runs to see the raw performance. We are running additional experiments and we\’ll try compaction out as well.
Also, benchmark A is running RF=2 instead of 3 (the # used for Cassandra)
Apologies for the delayed response. We are preping for the upcoming conference in the bay area
Cassandra on a 300 node cluster recommends RF=3. We do recommend additional replicas in large node counts as well in Couchbase Server. The rationale is: the chances for failure of \”more than 1 node\” increase with the node count. You could argue this either way but given Couchbase node count is much smaller (50 couchbase server), the protection you get from 2 replicas is higher than a cluster of 6x the size (300 nodes in cassandra).
Why don\’t you use more small nodes ? n1-highmem-4 instead of n1-standard-16.
Your latencies are relatively high compare to aerospike benchmark …
Maybe you should have better performance with 100 smaller nodes and reduce the price too.
You can also use local SSD to have the same configuration than aerospike benchmark :-)
Can you make the same benchmark with the beta version of Couchbase with ForestDB ? *_*
Impressive results. However, I must take issue with your intro where you state: \”Google posted a set of results on Google Cloud blog post here\”. The reality is that *you* wrote the Google blog post as a guest author. Not doubting your numbers, but the way you put it makes it sound like Google independently set out to test Couchbase performance on their platform, thus lending an air of (additional) legitimacy to the findings. You should be more clear about this.
Can you share the benchmark with compaction enabled?
yes!
these tests are NOT realistic at all.
only \”initial load\”, not real usage.
In real life you\’d run out of storage space in no time.
Thumbs down.
cbc-pillowfight utility uses payload that is very easy to compress.
Here payload of 2000 was reduced to 111 bytes by libsnappy.
This is completely incorrect to test write performance on such payload, Cihan.
/opt/couchbase/bin/couch_dbdump 451.couch.28 |head
Dumping \”451.couch.28\”:
Doc seq: 45380
id: 00000000000000643031
rev: 24
content_meta: 131
size (on disk): 111
cas: 41835853675421190, expiry: 0, flags: 0, datatype: 0
size: 2000
data: (snappy) ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?
Doc seq: 47573
id: 00000000000000069855
(added https://issues.couchbase.com/b… about the randomness of cbc-pillowfight payload)
Can you provide how the number of nodes and sizes will translate into # of ec2 nodes and the instance sizes in AWS?
[…] Бенчмарк один, бенчмарк два, бенчмарк три [PDF]; […]