Here’s the home page for the series: https://www.couchbase.com/blog/couchbase-oracle-developers-part-2-architecture/
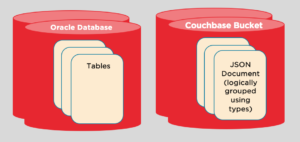
Oracle DBAs work with clusters, machines, storage systems, disks, etc. Oracle developers and their applications work with databases, tables, rows, columns, partitions, users, data types within the Oracle database system. Let’s compare and contrast how this is done on Couchbase.
| Topic | Oracle | Couchbase | ||||
| Database | Database | Within a Couchbase instance (single node or multi-node cluster), you can create one or more buckets. From the developer perspective, you create buckets and start inserting JSON of various types into buckets.
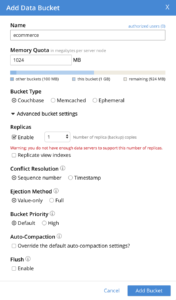
CREATE: You create bucket either via Couchbase web console or via REST API. In the web console, you provide the information below.
User provides the following: Name of a bucket. Location of an existing data storage. Couchbase creates a directory with the bucket name underneath the specified directly. In this case, CUSTOMER directory is created under : /my/data. This directory /my/data should exist on every node of the Couchbase cluster with data (key-value) service. This is fixed and unchangeable. Memory used in megabytes. This is the fixed amount of memory used to cache the data as you insert/load the data. The actual data in memory depends on your application access pattern. Usual LRU, MRU algorithms are used to determine which documents are kept in memory and which ones are evicted. For additional information on key eviction, see the link: Bucket Type Couchbase: JSON database Memcached: Memcache Ephemeral: just like Couchbase bucket, except all the data, index are only in memory. Replica: By default there is one copy of the data in the cluster. You can have up to three copies of the data within the cluster. Under the CAP theorem rules. There are plenty of papers and talks on CAP theorem and their application to NoSQL databases in public domain.Couchbase Bucket is a CP system. That means, Couchbase chooses consistency over availability (C over A). Supporting partition tolerance is a requirement for these multi-node scale out systems. See Couchbase documentation for full details on all the parameters and examples. http://bit.ly/2GrbMOw |
||||
| Table | Table | Right now, Couchbase Bucket serves two purposes.
As we discussed earlier, there could be up to 10 buckets in a Couchbase system. In RDBMS, you store a row that belongs to a domain in a single table. In Couchbase, you model your document to contain as much data about the object as possible. For example, the CUSTOMER object can contain not only the basic customer information but also the customer orders so a single GET operation can get the whole customer information quickly. Example document INSERT via N1QL:
Note that there was no CREATE TABLE for CUSTOMER. You simply and directly insert the JSON document into the bucket. You do need a bucket-unique document. This unique is modeled on primary key for a table. If you have multiple parts, separate them by a delimiter like a hyphen, underscore or a period. Now you have the CUSTOMER document in the bucket named e-commerce. Now, you want another type of document, say PARTNER. You can simply create a separate bucket called PARTNER. OR, you can insert the PARTNER documents into the same BUCKET. Insert into a separate bucket is straightforward. In Couchbase, it’s a common and recommended practice to use the same bucket to store documents of multiple types for an application. This has two advantages.
|
||||
| Row | Row | JSON Document, with it’s documentkey.
Considerations for document key design: http://bit.ly/2GnRwwV |
||||
| Column | Column | JSON is made up of key-value pairs.
Example: {“fullname”: “Joe Smith”} {“name: { “fname”:”Joe”, “lname”:”Smith”} {“hobbies”: [“lego”,”robotics”, “ski”]} In these documents, “name” is a key, also known as an attribute. Its value can be scalar (fullname) or an object (name) or array (hobbies). In Oracle, when you create the table, you specify column names and their data types. In Couchbase, you simply insert JSON documents. Each document self-describes the attribute (column) names. This gives you the flexibility to evolve the schema without having to lockdown the table. The data types are simply interpreted from the value itself: String, number, null, true, false, object or an array. |
||||
| Views | Views can be created with CREATE VIEW statement. Once created, these are simply relations that can be used anywhere a table (set of relations) can be used. There are some additional requirements for updates on views (e.g. instead of triggers for insert, updates on complex views). | Couchbase does not have dynamic SQL based view like Oracle. Couchbase does have a technology we call, “Couchbase Views”, based on map reduce framework. These are similar to materialized views and not the SQL View and cannot be used with N1QL. | ||||
| Materialized Views (aka Materialized Query Tables) | Materialized Views | Couchbase VIEW provides a flexible map-reduce framework for you to create pre-aggregations, indexes, anything else you want to create. See more details at: http://bit.ly/2EhIFfF | ||||
| Sequences | Sequences | Unavailable | ||||
| Triggers | Triggers | Triggers are not available.
Expiry (TTL: time to live) settings give you ability to automatically trigger deletion of a document after certain period. http://bit.ly/2DFe7U2 |
||||
| Constraints | Constraints: primary key, unique, Check, referential, not null, | Couchbase requires and enforces unique constraint on the document key within a bucket. Documents can have reference to other document’s key. It’s simply storing the data and can be used in JOIN operations. The reference itself isn’t checked or enforced. | ||||
| Indexes | Indexes | Index. More details in the Index section. For now, you can see the detailed blog: http://bit.ly/2DI1nAa |