
When it comes to machine learning, a lot is said and written about training your ML models. But of equal importance is where you store those models once you’re ready to serve up real-time predictions.
Last week, we looked at five use cases for using Couchbase with your real-time prediction serving system. We explored how Couchbase is used to store input or features that are later passed to the machine learning (ML) models, model metadata, and the predictions themselves.
In this article, we’ll explore how to use Couchbase Server to store trained ML models.
Online Machine Learning and the Need for a Fast Model Store
Traditionally, a machine learning model is trained offline on large amounts of historical data and then deployed in production for serving predictions.
However, offline training may not always be possible. For example, sometimes small startups may not have access to large quantities of training data. This might also be the case in established enterprises where a team is starting on a new ML use case that does not have enough training data. As a result, waiting for sufficient training data availability impacts the time to market for your product.
To address this problem, some companies use online machine learning. In this approach, companies train an initial model using small amounts of data, deploy it in production and then incrementally retrain it as more data becomes available. A company may need to deploy thousands of such models in production, each handling a different use case.
With online machine learning, the models may need to be updated very frequently. At the same time, predictions continue to be served using the newly updated models. A high throughput, low read and write latency data store is needed to store the ML models.
Storing Machine Learning Models on Couchbase
The Couchbase Data Platform satisfies the performance requirements of online machine learning. Its memory-first architecture – with integrated document cache – delivers sustained high throughput and consistent sub-millisecond latency.
Couchbase Server stores any of your ML models, either in binary or JSON format, up to 20MB in size (i.e., the Couchbase document limit). Your models are stored in Couchbase buckets (or “Collections”) and you access them just like any other data stored on Couchbase. This makes lifecycle management of ML models easy for you since models are updated with a simple key-value update.
Binary vs JSON Model Formats
One advantage of storing the ML model in binary format is that you don’t need to convert from JSON to binary at the time of making predictions. Binary models are also smaller in size.
However, storing the model in JSON format allows users to look inside the model via various Couchbase interfaces. This may be useful for those users who care about AI explainability and don’t want the ML model to be a black box.
Another advantage of storing the model in JSON format is that the Couchbase Query service or Full-Text Search service can index and query the model. The Couchbase Data Platform includes all of these services and eliminates the need for separate products.
Couchbase also meets other requirements that a production ML system requires of its model store such as high availability, ability to dynamically scale with increased workload, secure data access and ease of management.
ML Model Formats & ONNX
A variety of ML frameworks such as scikit-learn and TensorFlow are available to help train and deploy models. Data scientists typically build models using the framework and language they are most familiar with, or they pick a framework more suitable for model training.
Sometimes the model is deployed in production using the same language and framework as the ones used during training. This approach provides ease of use. However, the language or framework that works best for training may not be optimal for making predictions.
It’s common for users to convert the trained model to a different framework or rewrite it in a different language. Open Neural Network Exchange (ONNX) is a popular model interchange format used for this purpose.
Models trained in a variety of popular frameworks can be converted to ONNX. You can then export the ONNX model to another framework more suitable for deployment. Or you can keep the model in the ONNX format and deploy it on one of the supported runtimes such as the open source ONNX runtime.
ONNX runtime is supported on Linux, Windows, and Mac with bindings available for various languages such as Python and Java. Please refer to ONNX runtime for more details.
Serialization & Deserialization of ML Models
Trained models are typically serialized and saved in some format to a file and then deserialized to restore and load them during deployment. For example, pickle is a Python specific format that allows a scikit-learn model to be stored as a byte stream.
Let’s take a look at how a machine learning model can be trained, serialized and stored on Couchbase and then retrieved, deserialized and used for making predictions.
We will train a model (a support vector machine (SVM) classifier) to predict the type of iris flower based on the dimensions of its sepal and petals. We will use the Iris dataset to train the model using the scikit-learn framework. This dataset contains sepal and petal dimensions for three different types of the iris flower for a total of 150 rows.
Using Couchbase as a ML Model Store: Binary Format
Training & Serialization Workflow
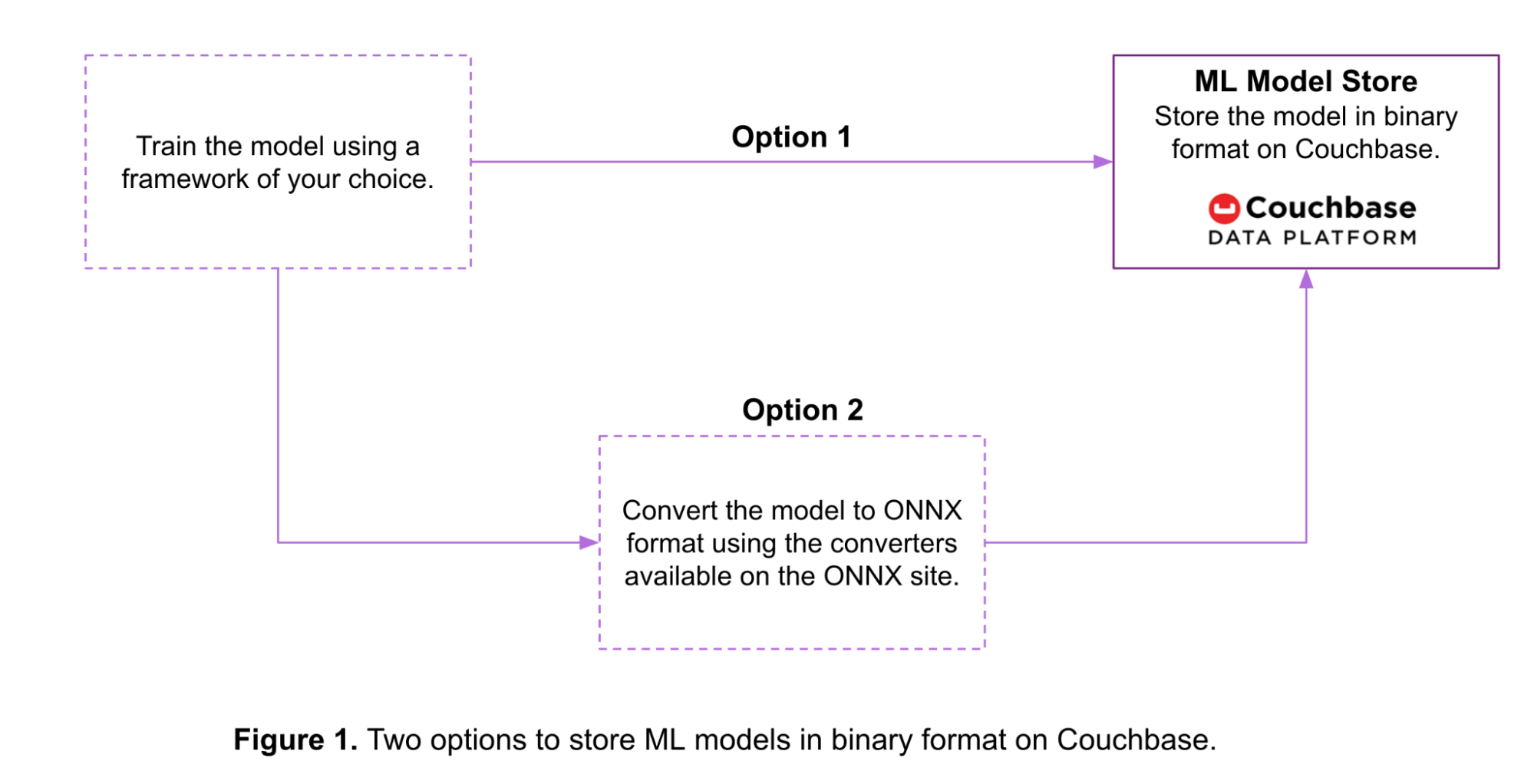
As shown in Figure 1 below, there are two options to store a ML model in binary format on Couchbase:
- Option 1: Models trained in various ML frameworks are converted to a byte stream using tools provided by the framework itself. Models are then stored in that format within a Couchbase bucket.
- Option 2: Trained models are converted into the ONNX format before being stored in Couchbase. Here are some available conversion tools for various ML frameworks.
Below is some example code for Option 2. In this example:
- A SVM classifier is trained on the iris dataset using the scikit-learn framework.
- The trained model is converted from scikit-learn into the ONNX format using the converter available here.
- The ONNX model is then stored in a Couchbase bucket called
ModelRepositoryusing the Couchbase Python SDK. Read more about available Couchbase SDKs here.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
# Step-1: Train a scikit-learn model from sklearn import svm from sklearn import datasets clf = svm.SVC() X, y = datasets.load_iris(return_X_y = True) clf.fit(X, y) # Step-2: Convert the scikit-learn model into ONNX format from skl2onnx import convert_sklearn from skl2onnx.common.data_types import FloatTensorType initial_type = [('float_input', FloatTensorType([None, 4]))] onx = convert_sklearn(clf, initial_types = initial_type) # Step-3: Store the ONNX model in binary format in a # Couchbase Bucket from couchbase.cluster import Cluster from couchbase.cluster import PasswordAuthenticator from couchbase import FMT_BYTES cluster = Cluster(host) authenticator = PasswordAuthenticator(user_name, password) cluster.authenticate(authenticator) modelBucket = cluster.open_bucket('ModelRepository') key = "iris.onnx" value = onx.SerializeToString() modelBucket.upsert(key, value, format = FMT_BYTES) |
Deserialization & Prediction Workflow
The prediction serving system reads the model from Couchbase and generates the prediction (e.g., the type of Iris flower).
Here is the code for reading the model that was stored on Couchbase in the previous example.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# Read the ONNX model from Couchbase # Note the steps to connect to the Couchbase bucket # are as shown in the previous example rv = modelBucket.get("iris.onnx") onnxModel = rv.value # Predict using ONNX runtime. import onnxruntime as rt import numpy sess = rt.InferenceSession(onnxModel) input_name = sess.get_inputs()[0].name label_name = sess.get_outputs()[0].name prediction = sess.run([label_name], {input_name: X[0:3].astype(numpy.float32)})[0] |
This model is then used to generate a prediction using the ONNX runtime. Predictions are generated on the first three rows of input array X that was obtained in the previous example.
It’s also possible to split the dataset into training and test data and generate predictions on the test data.
Using Couchbase as a ML Model Store: JSON Format
Training & Serialization Workflow
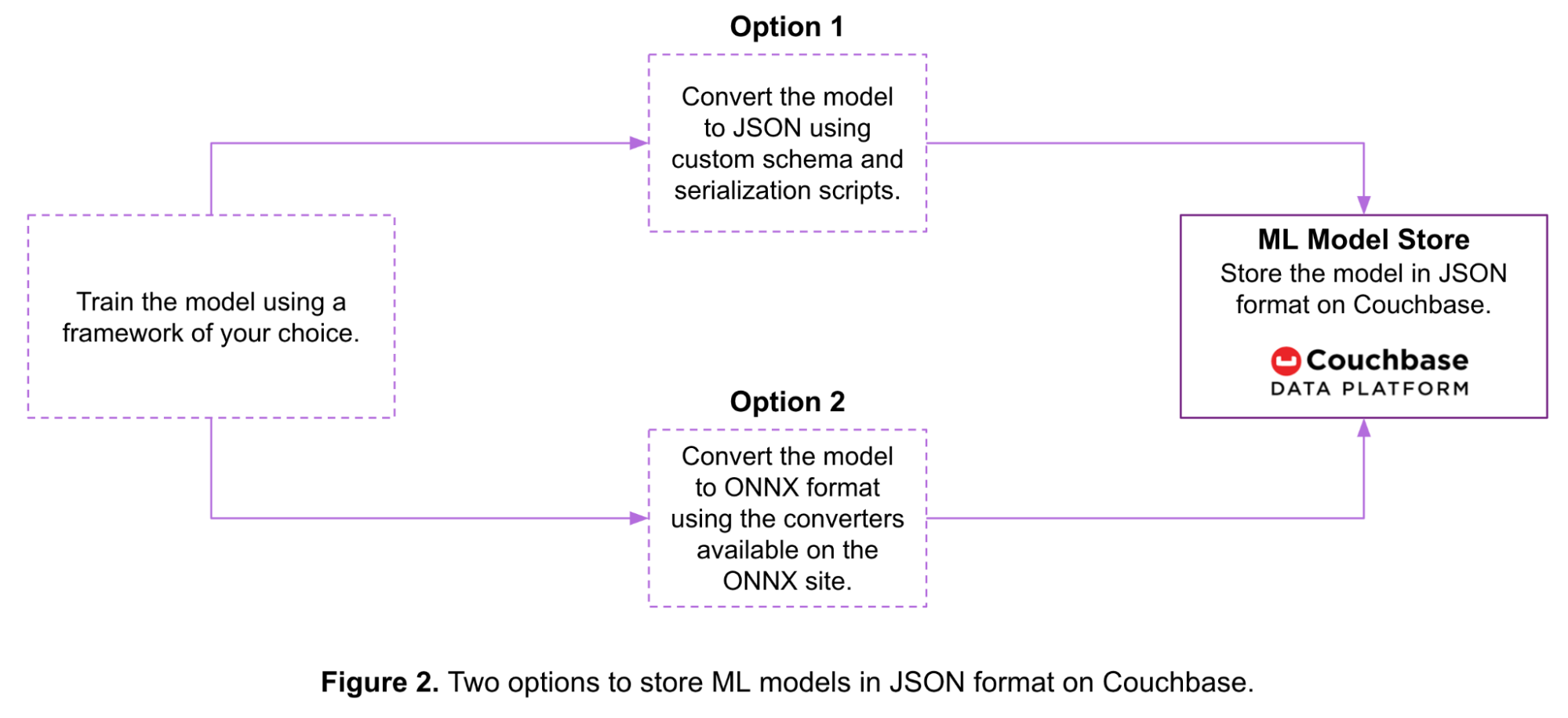
Figure 2 below shows two options to store a machine learning model as a JSON document in Couchbase:
- Option 1: You can serialize the model using a custom schema and scripts before storing it on Couchbase.
- Option 2: You can convert the model into the ONNX format and then store it on Couchbase.
Here is some example code for Option 2:
|
1 2 3 4 5 6 7 8 9 10 11 |
# Steps 1 and 2 to train the model and convert it into the ONNX # format as well the steps to connect to a Couchbase bucket # are the same as the one in the earlier binary model example. # Step-3: Convert the ONNX model to JSON & store in a # Couchbase bucket from google.protobuf.json_format import MessageToJson import json key = "iris_json.onnx" value = json.loads(MessageToJson(onx)) modelBucket.upsert(key, value) |
Deserialization & Prediction Workflow
Here is the deserialization code for reading the model that was stored on Couchbase in the earlier example. This model is then used to generate a prediction using the ONNX runtime.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
# Read the ONNX-JSON model from Couchbase # Note the steps to connect to the Couchbase bucket # are as shown in the earlier example rv = modelBucket.get("iris_json.onnx") # Convert the ONNX-JSON model to ONNX object from onnx import ModelProto from google.protobuf.json_format import Parse model = ModelProto() Parse(json.dumps(rv.value), model) onnxModel1 = model.SerializeToString() # Predict using ONNX runtime import onnxruntime as rt import numpy sess = rt.InferenceSession(onnxModel1) input_name = sess.get_inputs()[0].name label_name = sess.get_outputs()[0].name prediction1 = sess.run([label_name], {input_name: X[0:3].astype(numpy.float32)})[0] |
Online Machine Learning using Couchbase as a ML Model Store
Couchbase can be used to store your ML models for online machine learning.
Figure 3 below shows the flow for online learning and predictions with models stored on the Couchbase Data Platform.
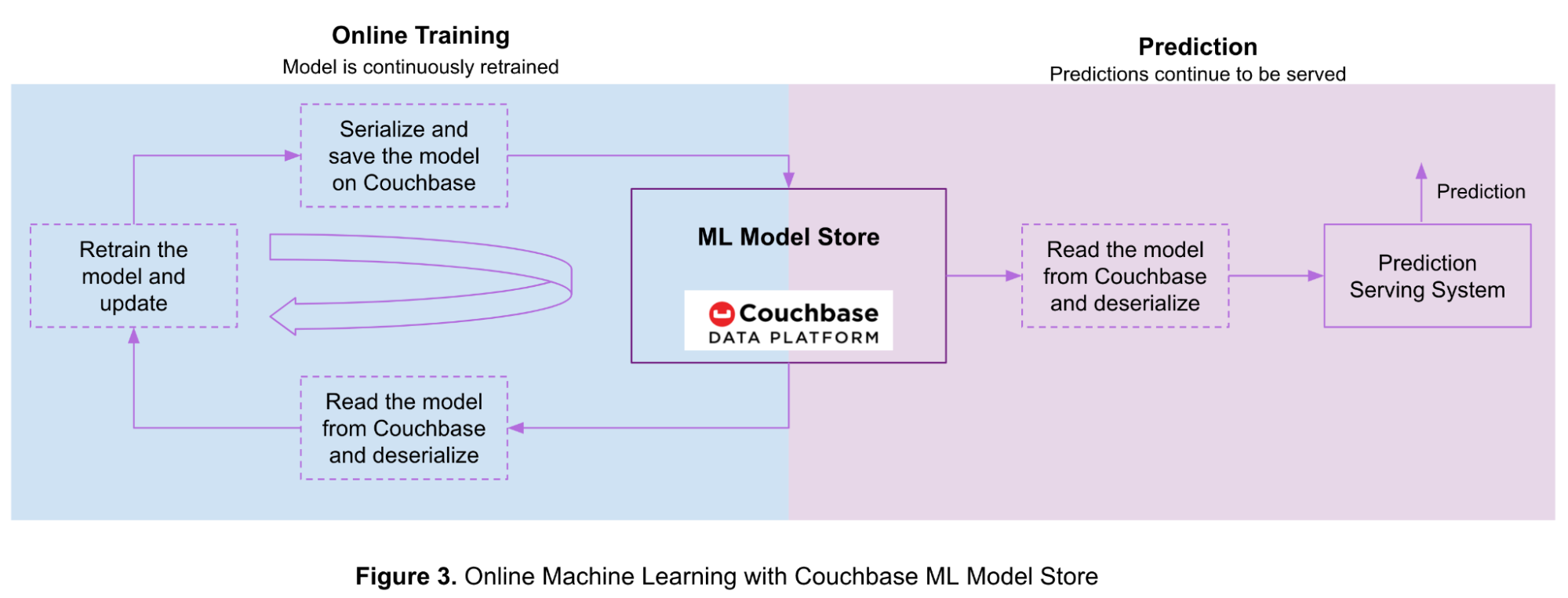
You first train the model offline with a small amount of training data, then serialize it and store it in a Couchbase bucket. As more data becomes available, your ML model is continuously updated using online learning.
Steps for using Couchbase for online machine learning are as follows:
- Read the model from Couchbase and deserialize it using the steps mentioned in the earlier sections.
- Retrain the model using newly available training data..
- Serialize the updated model and save it in a Couchbase bucket using the steps described in the earlier sections.
- Return to step 1 as more training data becomes available.
Your prediction serving system continues to serve predictions during this process following these steps:
- Read the model from Couchbase and deserialize it using the steps mentioned in earlier sections.
- Generate prediction.
The architecture of the most common prediction serving systems are described in last week’s article: 5 Use Cases for Real-Time Prediction Serving Systems with Couchbase.
Conclusion
As shown in Figure 4 below, you can replace multiple data store products with the single Couchbase Data Platform. This approach reduces complexity, operational overhead and total cost of ownership (TCO).
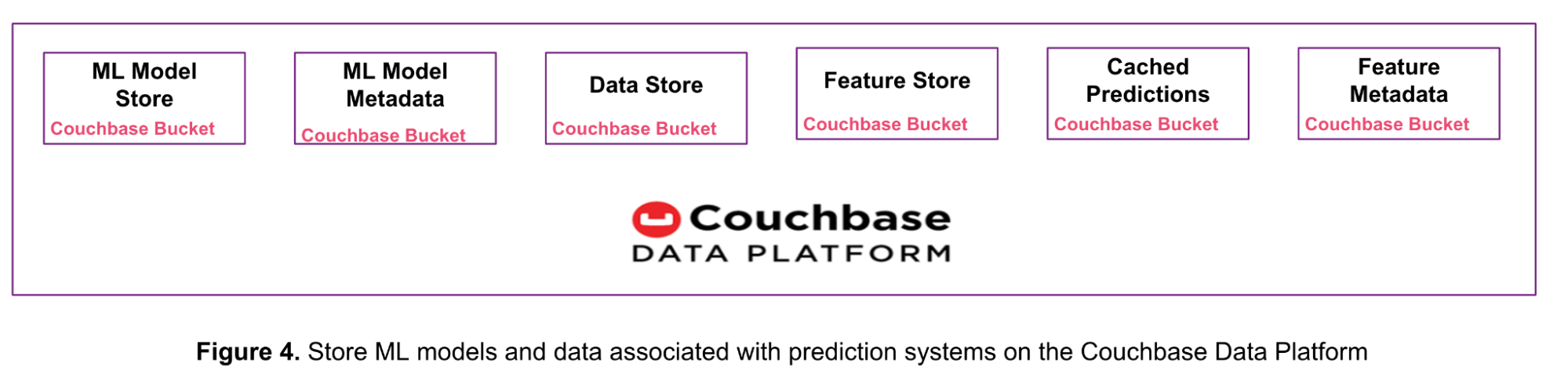
We saw in this article how the Couchbase Data Platform stores ML models up to 20MB in size and how it’s used for online machine learning.
Last week, we looked at 5 Use Cases for Real-Time Prediction Serving Systems with Couchbase and learned how the Couchbase Data Platform can store raw input data, features, predictions, feature metadata and model metadata.
Each of these types of data can be stored in a separate Couchbase bucket or collection. A collection is a data container within a bucket to logically group similar items. This feature was introduced with Couchbase Server 7.0. Refer to the documentation on Scopes and Collections in Couchbase for more information.
Next Steps
If you’re interested in learning more about machine learning and Couchbase, here are some great next steps and resources to get you started:
- Start your free trial of Couchbase Cloud – no installation required.
- Dive deeper into the technical details with this white paper: Couchbase Under the Hood: An Architectural Overview.
- Explore the Query, Full-Text Search, Eventing, and Analytics services that Couchbase delivers.