
If you’re a developer who’s new to Couchbase, this article helps you get started.
This weekly walkthrough series helps you understand the basics of connecting to Couchbase, shows you how to retrieve and modify data in Couchbase Server, how to use the SQL++ query language (formerly known as N1QL) and more. This week, the example code will feature Java, and we’ll be using the Couchbase Java SDK.
Couchbase is a distributed, JSON document database. It exposes a scale-out, key-value store with managed cache for sub-millisecond data operations, purpose-built indexers for efficient queries and a powerful query engine for executing SQL-like queries.
In this developer walkthrough, we will look at the basic features of Couchbase – both through a non-relational JSON interface and relational SQL interface. Couchbase ships with a sample database, travel-sample, and we’ll use this sample dataset to learn Couchbase fundamentals using the Java SDK.
Understanding the Travel-Sample Dataset
In order to gain a better understanding of what the travel-sample dataset looks like, feel free to read about it in the Java SDK documentation: Travel App Data Model.
Below is an entity-relationship diagram of the travel-sample dataset along with an accompanying data model:
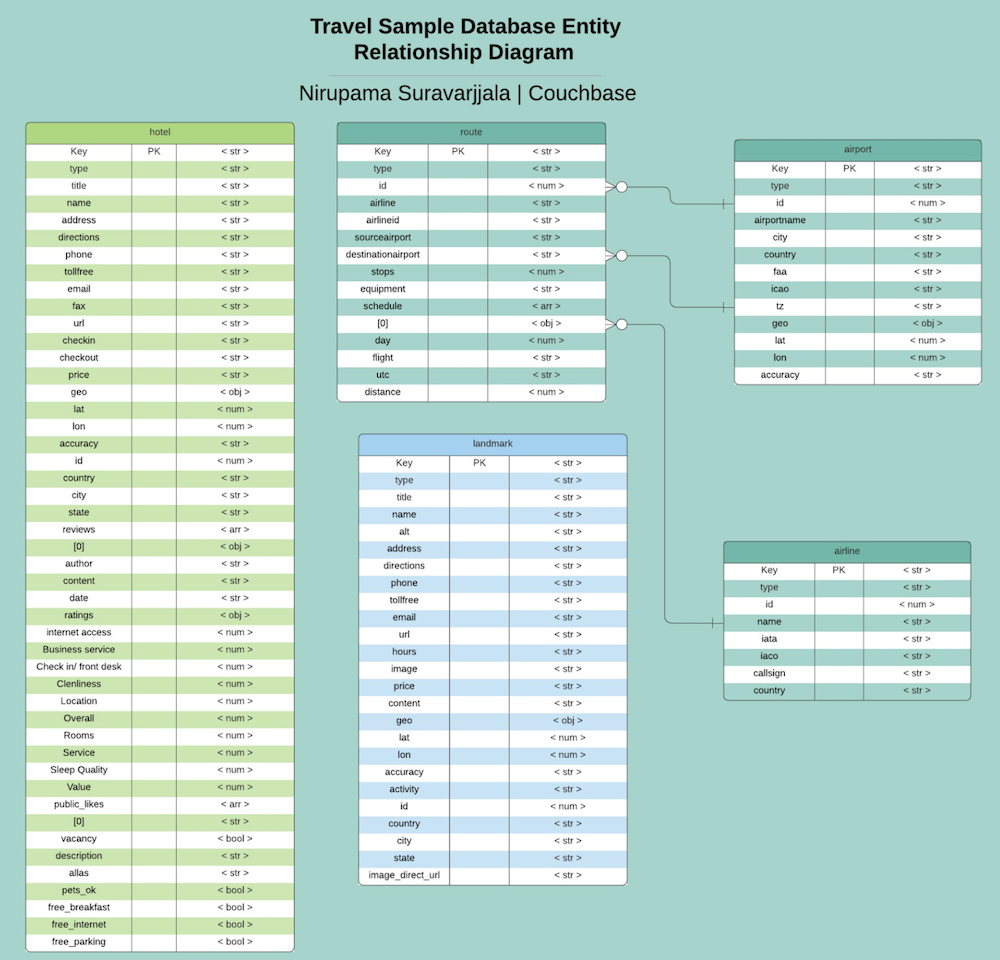

How to Use the Key-Value Get Function to Retrieve Data
Key-value (also known as the Couchbase Data Service) offers the simplest way to retrieve or mutate data where you know the key. A key-value store is a type of NoSQL database that uses a simple method to store data as a collection of key-value pairs in which a key serves as the unique identifier.
Couchbase Server is a key-value store that’s agnostic to what’s stored. The example below shows you how to use the key-value get function in order to retrieve data from a backend.
Before proceeding, make sure you’re familiar with the basics of authorization and connecting to a Couchbase cluster. Read the “Start Using the Java SDK” section of the Couchbase documentation if you need to catch up.
Below are the three imports you need:
|
1 2 3 |
import com.couchbase.client.core.error.DocumentNotFoundException; import com.couchbase.client.java.*; import com.couchbase.client.java.kv.*; |
Next, connect to the cluster that stores the data you want to retrieve. Because you’re using Java, first make sure you declare a class and a main method. Then create a variable for your cluster.
In the example below, cluster is the name of the variable of type var. Using a connection string, have your program connect with the data in the backend. A Couchbase connection string is a comma-delimited list of IP addresses and/or hostnames, optionally followed by a list of parameters. Below, couchbase://127.0.0.1 is a simple connection string with one seed node followed by a username and password. Be sure to replace all this information with information relative to your program.
|
1 2 3 4 5 |
class Program { public static void main(String[] args) { var cluster = Cluster.connect( "couchbase://127.0.0.1", "username", "password" ); |
A connection to a Couchbase Server cluster is represented by a cluster object. A cluster provides access to buckets, scopes and collections, as well as various Couchbase services and management interfaces.
After providing the connection string, username, and password above, you’re connected to a Couchbase cluster and can now connect to a Couchbase bucket and collection:
|
1 2 |
var bucket = cluster.bucket("travel-sample"); var collection = bucket.defaultCollection(); |
The Java get method allows you to retrieve a certain piece of data. Given a document’s key, you can use the collection.get() method to retrieve a document from a collection.
In this example, you’re retrieving the content in the collection named "airline_10" in the database. Then, in order to see the result, there is a print statement which allows you to finish retrieving the data.
|
1 2 3 4 |
try { var result = collection.get("airline_10"); System.out.println(result.toString()); } |
Lastly, just in case the user tries to retrieve a piece of information that does not exist or is not within the bounds of the document, there is a catch exception to make sure there are no errors in the code.
|
1 2 3 4 5 |
catch (DocumentNotFoundException ex) { System.out.println("Document not found!"); } } } |
Using the Query Method to Retrieve Data
A query is always performed at the cluster level, specifically using the query method. This method takes the statement as a required argument and then allows it to provide additional options if needed.
Once a result returns you can iterate the returned rows and/or access the QueryMetaData associated with the query. If something goes wrong during the execution of the query, a derivative of the CouchbaseException is thrown that also provides additional context on the operation.
Below are the five imports you need:
|
1 2 3 4 5 |
import com.couchbase.client.core.error.DocumentNotFoundException; import com.couchbase.client.java.*; import com.couchbase.client.java.kv.*; import com.couchbase.client.java.json.JsonObject; import com.couchbase.client.java.query.QueryResult; |
Then, connect to the cluster that stores the data you want to retrieve, following similar steps as before. Be sure to replace all this information with information relative to your program.
|
1 2 3 4 5 |
class Program { public static void main(String[] args) { var cluster = Cluster.connect( "couchbase://127.0.0.1", "username", "password" ); |
As before, you’re connected to a Couchbase cluster and can now connect to a Couchbase bucket:
|
1 |
var bucket = cluster.bucket("travel-sample"); |
This is an example of performing a query and handling the results. The result that prints is "Hotel: " followed by the name, city, state and other information specific to the hotel. Only up to five rows will be printed since that is the number limit represented in the code. In order to test out different queries, try changing the name of the city in line six to any other city.
|
1 2 3 4 5 6 7 8 9 10 11 |
try { var query = "SELECT h.name, h.city, h.state " + "FROM `travel-sample` h " + "WHERE h.type = 'hotel' " + "AND h.city = 'Malibu' LIMIT 5;"; QueryResult result = cluster.query(query); for (JsonObject row : result.rowsAsObject()) { System.out.println("Hotel: " + row); } |
As before, the catch exception ensures there are no errors in your code. For example, if you chose a city that your database doesn’t have, this DocumentNotFoundException exception will print "Document not found!".
|
1 2 3 4 5 |
} catch (DocumentNotFoundException ex) { System.out.println("Document not found!"); } } } |
How to Query with Named Parameters
As mentioned previously, query methods allow you to search for specific information in a database based on certain criteria. Query methods can have named or positional parameters.
In this section, we’ll go over what named parameters are and how they are useful when calling methods with a vast number of parameters. Named parameters clearly state the name of the parameter when invoking a method. They allow users to invoke the method with a random subset of them, using default values for the rest of the parameters.
Below are the seven imports you need:
|
1 2 3 4 5 6 7 |
import com.couchbase.client.core.error.CouchbaseException; import com.couchbase.client.java.*; import com.couchbase.client.java.kv.*; import com.couchbase.client.java.json.JsonObject; import com.couchbase.client.java.query.QueryResult; import com.couchbase.client.java.query.QueryOptions; import static com.couchbase.client.java.query.QueryOptions.queryOptions; |
Then, connect to the cluster that stores the data you want to retrieve, following similar steps as before. Be sure to replace all this information with information relative to your program.
|
1 2 3 4 5 |
class Program { public static void main(String[] args) { var cluster = Cluster.connect( "couchbase://127.0.0.1", "username", "password" ); |
As before, you’re connected to a Couchbase cluster and can now connect to a Couchbase bucket:
|
1 |
var bucket = cluster.bucket("travel-sample"); |
The code proceeds to access the travel-sample database and specifically the name, city and state buckets. The queryOptions() method allows the customization of various SQL++ query options.
In the code below, the result brings back data of types: hotel and city: Malibu. Since the limit is five, only up to five rows are printed. The result that’s printed is "Hotel: " followed by information including the name and city.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
try { var query = "SELECT h.name, h.city, h.state " + "FROM `travel-sample` h " + "WHERE h.type = $type " + "AND h.city = $city LIMIT 5;"; QueryResult result = cluster.query(query, queryOptions().parameters( JsonObject.create() .put("type", "hotel") .put("city", "Malibu") )); |
The result is taken from the travel-sample database, specifically from the rows. The .stream method is used to compute elements as per the primary method without changing the original value of the JSON object.
|
1 2 3 4 |
result.rowsAsObject().stream().forEach( e-> System.out.println( "Hotel: " + e.getString("name") + ", " + e.getString("city")) ); |
As before, the catch exception ensures there are no errors in your code. For example, if you chose a city or type of place that our database does not have, this CouchbaseException exception will print "Exception: " along with the string representation of the object that is causing the error.
|
1 2 3 4 5 |
} catch (CouchbaseException ex) { System.out.println("Exception: " + ex.toString()); } } } |
How to Query with Positional Parameters
As mentioned previously, query methods can have named or positional parameters. We covered named parameters above.
In this section, we’ll go over positional parameters and how they’re useful when calling methods with a vast number of parameters. Positional parameters allow the order of the method parameters to be replaced with placeholders.
For example, the first placeholder is replaced with the first method parameter, the second placeholder is replaced with the second method parameter, and so on.
Below are the seven imports you need:
|
1 2 3 4 5 6 7 |
import com.couchbase.client.core.error.CouchbaseException; import com.couchbase.client.java.*; import com.couchbase.client.java.kv.*; import com.couchbase.client.java.json.JsonArray; import com.couchbase.client.java.query.QueryResult; import com.couchbase.client.java.query.QueryOptions; import static com.couchbase.client.java.query.QueryOptions.queryOptions; |
Then, connect to the cluster that stores the data you want to retrieve, following similar steps as before. Be sure to replace all this information with information relative to your program.
|
1 2 3 4 5 |
class Program { public static void main(String[] args) { var cluster = Cluster.connect( "couchbase://127.0.0.1", "username", "password" ); |
As before, you’re connected to a Couchbase cluster and can now connect to a Couchbase bucket:
|
1 |
var bucket = cluster.bucket("travel-sample"); |
The query below searches for the name, city and state from the travel-sample database taking into account specifically the type of place and the city. Later on, these are revealed as hotels in Malibu.
|
1 2 3 4 5 6 7 8 9 |
try { var query = "SELECT h.name, h.city, h.state " + "FROM `travel-sample` h " + "WHERE h.type = $1 " + "AND h.city = $2 LIMIT 5;"; QueryResult result = cluster.query(query, queryOptions().parameters(JsonArray.from("hotel", "Malibu")) ); |
As with the named parameters example above, the .stream method is used to compute elements as per the primary method without changing the original value of the JSON object.
|
1 2 3 4 |
result.rowsAsObject().stream().forEach( e-> System.out.println( "Hotel: " + e.getString("name") + ", " + e.getString("city")) ); |
How to Use Sub-Document Lookup Operations
Sub-documents are parts of the JSON document that you can atomically and efficiently update and retrieve.
While full-document retrievals retrieve the entire document and full-document updates require sending the entire document, sub-document retrievals only retrieve relevant parts of a document and sub-document updates only require sending the updated portions of a document. You should use sub-document operations whenever you’re modifying only portions of a document, and full-document operations only when the contents of a document are going to change significantly.
The sub-document operations described in this article are for key-value requests only; they are not related to sub-document SQL++ queries. In order to use sub-document operations you need to specify a path indicating the location of the sub-document.
The lookupIn operation queries the document for a certain path(s) and returns that path(s). You have a choice of actually retrieving the document path using the subdoc get sub-document operation, or simply querying the existence of the path using the subdoc exists sub-document operation. The latter saves even more bandwidth by not retrieving the contents of the path if it is not needed.
Below are the five imports you need:
|
1 2 3 4 5 |
import com.couchbase.client.core.error.DocumentNotFoundException; import com.couchbase.client.java.*; import com.couchbase.client.java.kv.LookupInResult; import static com.couchbase.client.java.kv.LookupInSpec.get; import java.util.Collections; |
Then, connect to the cluster that stores the data you want to retrieve, following similar steps as before. Be sure to replace all this information with information relative to your program.
|
1 2 3 4 5 |
class Program { public static void main(String[] args) { var cluster = Cluster.connect( "couchbase://127.0.0.1", "username", "password" ); |
As before, you’re connected to a Couchbase cluster and can now connect to a Couchbase bucket:
|
1 2 |
var bucket = cluster.bucket("travel-sample"); var collection = bucket.defaultCollection(); |
In the code below, the lookupInoperation queries the airport_1254 document for a certain path, the geo.alt path. This code allows us to retrieve the document path using the subdoc get sub-document operation: (get("geo.alt")).
|
1 2 3 4 5 6 7 8 |
try { LookupInResult result = collection.lookupIn( "airport_1254", Collections.singletonList(get("geo.alt")) ); var str = result.contentAs(0, String.class); System.out.println("Altitude = " + str); |
As before, the catch exception ensures there are no errors in your code. For example, if you chose a city that our database does not have, this DocumentNotFoundException exception will print "Document not found!".
|
1 2 3 4 5 |
} catch (DocumentNotFoundException ex) { System.out.println("Document not found!"); } } } |
How to Use Sub-Document Mutation Operations
Sub-document mutation operations modify one or more paths in the document.
The simplest of these operations is subdoc upsert. Just like the fulldoc-level upsert, the subdoc upsert operation either modifies the value of an existing path or creates it if it doesn’t exist. Likewise, the subdoc insert operation only adds the new value to the path if it doesn’t exist.
Below are the eight imports you need:
|
1 2 3 4 5 6 7 8 |
import com.couchbase.client.core.error.subdoc.PathNotFoundException; import com.couchbase.client.core.error.subdoc.PathExistsException; import com.couchbase.client.java.*; import com.couchbase.client.java.kv.LookupInResult; import static com.couchbase.client.java.kv.LookupInSpec.get; import static com.couchbase.client.java.kv.MutateInSpec.upsert; import java.util.Collections; import java.util.Arrays; |
Then, connect to the cluster that stores the data you want to retrieve, following similar steps as before. Be sure to replace all this information with information relative to your program.
|
1 2 3 4 5 |
class Program { public static void main(String[] args) { var cluster = Cluster.connect( "couchbase://127.0.0.1", "username", "password" ); |
As before, you’re connected to a Couchbase cluster and can now connect to a Couchbase bucket:
|
1 2 |
var bucket = cluster.bucket("travel-sample"); var collection = bucket.defaultCollection(); |
In the code below, the mutateIn operation is used to modify the "airline_10" by using a fulldoc-level upsert which will create the value of an existing path with parameters ("country", "Canada").
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
try { LookupInResult result = collection.lookupIn( "airline_10", Collections.singletonList(get("country")) ); var str = result.contentAs(0, String.class); System.out.println("Sub-doc before: "); System.out.println(str); } catch (PathNotFoundException e) { System.out.println("Sub-doc path not found!"); } try { collection.mutateIn("airline_10", Arrays.asList( upsert("country", "Canada") )); } catch (PathExistsException e) { System.out.println("Sub-doc path exists!"); } try { LookupInResult result = collection.lookupIn( "airline_10", Collections.singletonList(get("country")) ); var str = result.contentAs(0, String.class); System.out.println("Sub-doc after: "); System.out.println(str); |
As before, the catch exception ensures there are no errors in your code. For example, if you chose a document that your local computer does not have the pathway to, this PathNotFoundException exception will print "Sub-doc path not found!".
|
1 2 3 4 5 6 |
} catch (PathNotFoundException e) { System.out.println("Sub-doc path not found!"); } } } |
How to Use the Upsert Function
The Upsert function is used to insert a new record or update an existing one. If the document doesn’t exist it will be created. Upsert is a combination of insert and update.
Users executing the upsert statement must have the Query Update and Query Insert privileges on the target keyspace. If the statement has any returning clauses, then the Query Select privilege is also required on the keyspaces referred in the respective clauses. For more details about user roles, see the Authorization documentation on role-based access control (RBAC) in Couchbase.
Here’s a diagram of the basic syntax for all upsert operations:

Below are the nine imports you need:
|
1 2 3 4 5 6 7 8 9 |
import com.couchbase.client.core.error.subdoc.PathNotFoundException; import com.couchbase.client.java.*; import com.couchbase.client.java.kv.*; import com.couchbase.client.java.kv.MutationResult; import com.couchbase.client.java.json.JsonObject; import com.couchbase.client.java.kv.LookupInResult; import static com.couchbase.client.java.kv.LookupInSpec.get; import static com.couchbase.client.java.kv.MutateInSpec.upsert; import java.util.Collections; |
Then, connect to the cluster that stores the data you want to retrieve, following similar steps as before. Be sure to replace all this information with information relative to your program.
|
1 2 3 4 5 |
class Program { public static void main(String[] args) { var cluster = Cluster.connect( "couchbase://127.0.0.1", "username", "password" ); |
As before, you’re connected to a Couchbase cluster and can now connect to a Couchbase bucket:
|
1 2 |
var bucket = cluster.bucket("travel-sample"); var collection = bucket.defaultCollection(); |
The .put method allows for the user to insert a mapping into a map. This means you can insert a specific key (and the value it is mapping to) into a particular map. If an existing key is passed then the previous value gets replaced by the new value.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
JsonObject content = JsonObject.create() .put("country", "Iceland") .put("callsign", "ICEAIR") .put("iata", "FI") .put("icao", "ICE") .put("id", 123) .put("name", "Icelandair") .put("type", "airline"); collection.upsert("airline_123", content); try { LookupInResult lookupResult = collection.lookupIn( "airline_123", Collections.singletonList(get("name")) ); var str = lookupResult.contentAs(0, String.class); System.out.println("New Document name = " + str); |
As before, the catch exception ensures there are no errors in your code. For example, if you chose a document that your local computer does not have the pathway to, this PathNotFoundException exception will print "Document not found!".
|
1 2 3 4 5 6 |
} catch (PathNotFoundException ex) { System.out.println("Document not found!"); } } } |
Conclusion
I hope this introductory walkthrough helped you understand – and execute – some of the most common functions when working with Couchbase and the Java SDK. To dive into intermediate and advanced steps, check out the Java SDK documentation here.
If you need help or need some inspiration, check out the Couchbase Forums and connect with like-minded developers in the community.
As a next step, I encourage you to go through the free, online Couchbase Associate Java Developer Certification Course offered by Couchbase Academy.
Don’t just read about it, build something:<br/ >Get started with Couchbase 7 today