
As a developer advocate at Couchbase, I often travel around and meet people who either have no idea what NoSQL is, or more importantly what Couchbase is. For the people who are already familiar with NoSQL, Couchbase often gets compared with other NoSQL database products such as MongoDB and CouchDB, both of which have no affiliation to Couchbase.
I recently came across a MongoDB vs Couchbase comparison series by a community author, Milan Milosevic. In part one and part two of his series he explains his experience, as a seasoned MongoDB developer, coming from MongoDB, to trying to use Couchbase. Valid opinions are shared, but there are some things that may be overlooked.
I want to clear up some concerns on what makes Couchbase such a great option in the NoSQL space.
Buckets and the JSON Document
When working with data in Couchbase, you’re working with it as JSON formatted data. This JSON data can be as simple or as complex as you want to make it. For example, the following is a very valid JSON document:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
{ "firstname": "Nic", "lastname": "Raboy", "addresses": [ { "city": "San Francisco", "state": "California" }, { "city": "Mountain View", "state": "California" } ], "social": { "twitter": "https://www.twitter.com/nraboy", "blog": "https://www.thepolyglotdeveloper.com" } } |
Notice how in the above document you there are nested arrays of objects as well as nested objects? By working with JSON documents, you have more flexibility when it comes to your data than you would in a relational database.
Each JSON document stored in Couchbase must be given a unique id value, also known as a key. Couchbase won’t create this key for you, but there are many solutions available when it comes to key design. For example, here are three possible ways to design a key:
Human Readable
|
1 |
nraboy |
Computer Generated or Incrementing
|
1 |
caa80375-77e7-4714-b90a-1089e66a5fd5 |
Combination or Compound
|
1 |
nraboy::1 |
There are no right and wrong ways when it comes to creating a key. It really comes down to what your needs are in the particular document you are saving. Being able to design your own key is useful when it comes to establishing data relationships and querying that data.
Each JSON document, with its unique key, is saved to what is called a Couchbase Bucket. It is probably safe think of a Bucket like a literal bucket that you can store things in. You can place anything in this bucket regardless of its shape or size. The same applies to a Couchbase Bucket. For example, let’s say I wanted to save the following two documents:
|
1 2 3 4 5 |
{ "type": "person", "firstname": "Nic", "lastname": "Raboy" } |
We can give the document above any unique key, it doesn’t really matter for this example. The same rule applies to the following document:
|
1 2 3 4 5 |
{ "type": "location", "city": "San Francisco", "state": "California" } |
In both documents you’ll notice that they each have a type property with a different value. Also, each other property name is completely different, indicating that these documents solve different purposes. While not completely necessary, the type property helps us when querying these documents.
Does having X amount of document types in a single Bucket make things more complicated or messy? Absolutely not because querying is where it matters, not how your documents are stored.
When it comes to MongoDB, you’d store each document type in its own collection and likewise with an RDBMS where you’d store each in its own table. Does that mean MongoDB and a relational database like Oracle is doing it wrong or better than Couchbase? No it doesn’t, it is just their way of solving the problem.
Couchbase Shell (CBQ) and the Query Workbench
So with JSON data in Couchbase, there will be a need to query for it, or even create more of it. There are several ways to query for data in Couchbase and with several different tools.
With Couchbase Enterprise Edition and Community Edition you have what is called Query Workbench, which is a graphical tool for running queries, similar to what you’d find in phpMyAdmin or Oracle’s SQL Developer.
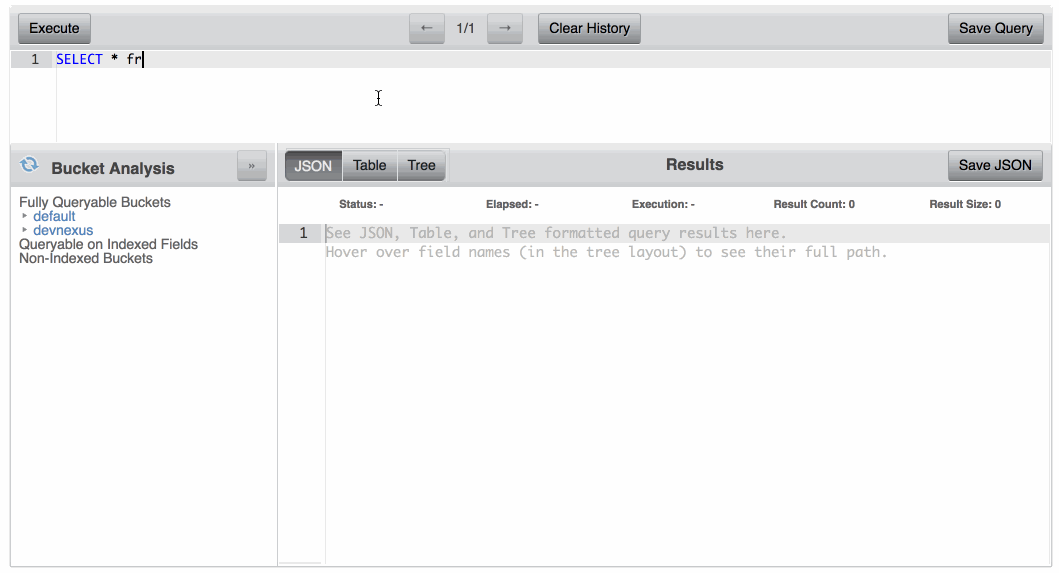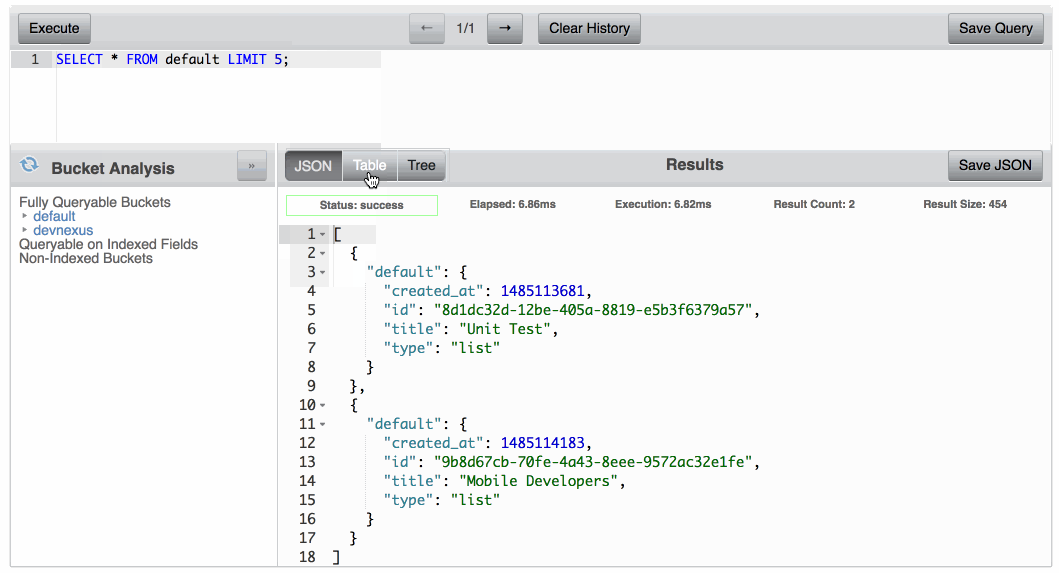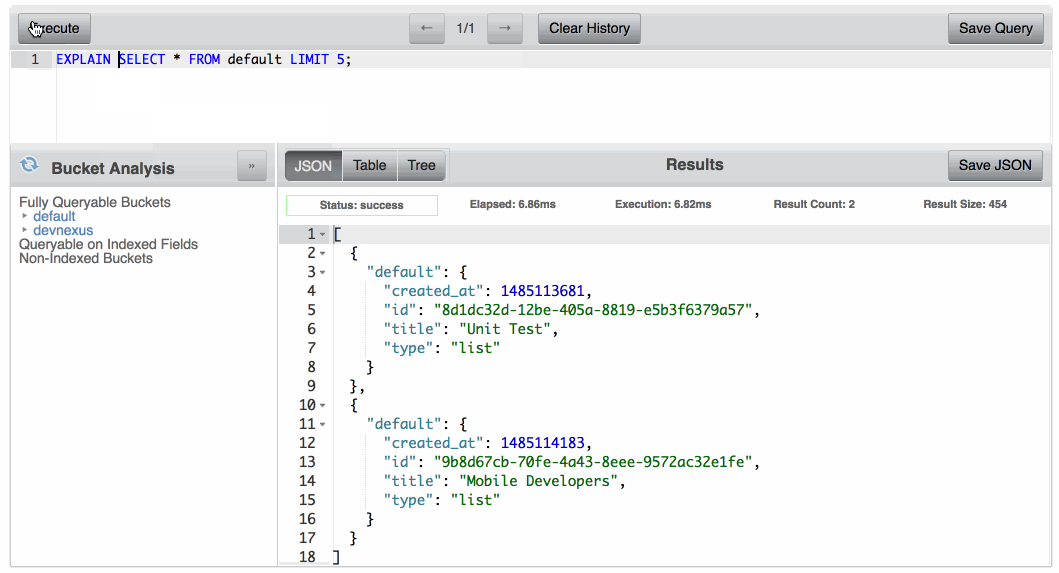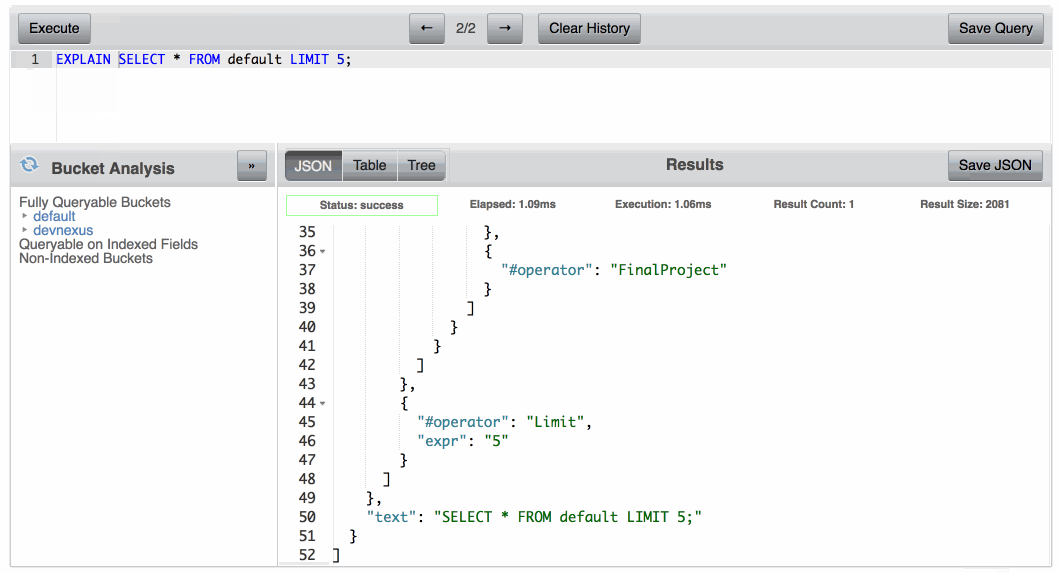
With Query Workbench you can execute Couchbase N1QL queries against documents found in each of your Buckets. These queries can include SELECT, INSERT, or any other query commands that are popular in SQL based languages. For example, the following query will return all properties of all documents found in the Couchbase Bucket named default:
|
1 |
SELECT * FROM default; |
While every NoSQL technology has its own methods for querying data, not only is N1QL easy to use, but it is more convenient for those moving away from a relational database that already have the SQL experience.
So what about the developers that would prefer to use a shell client? This is where the Couchbase Shell (CBQ) comes into play.
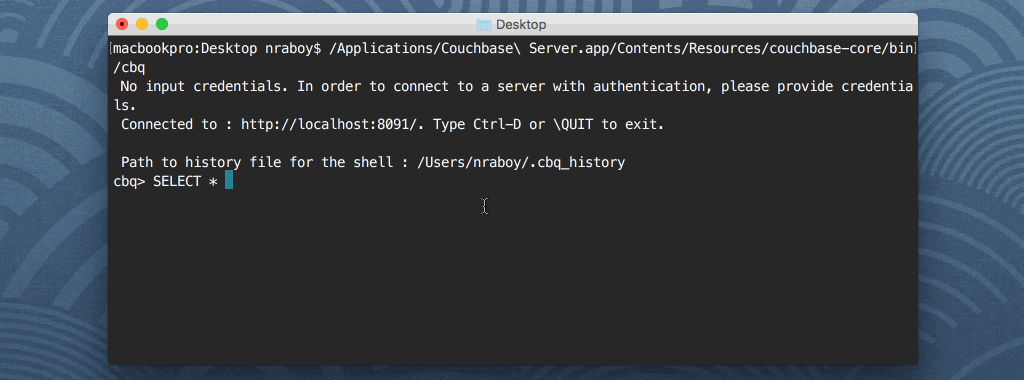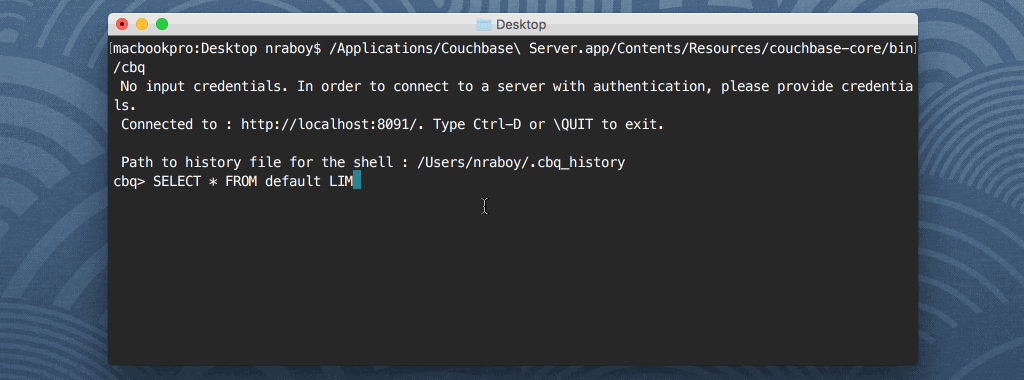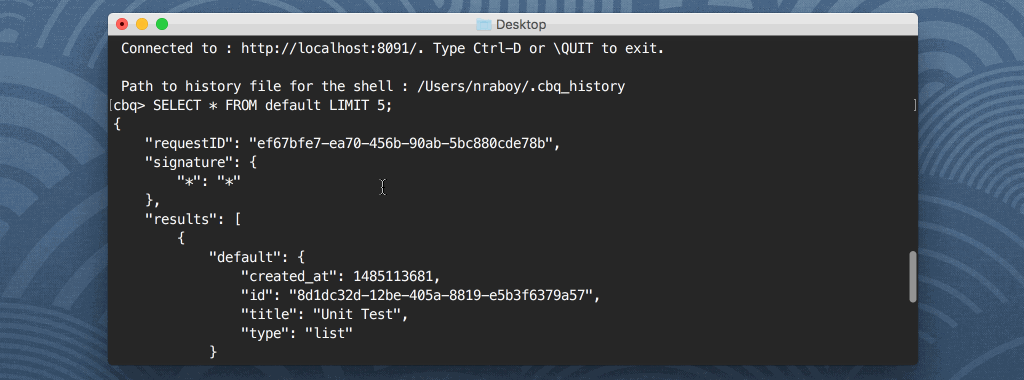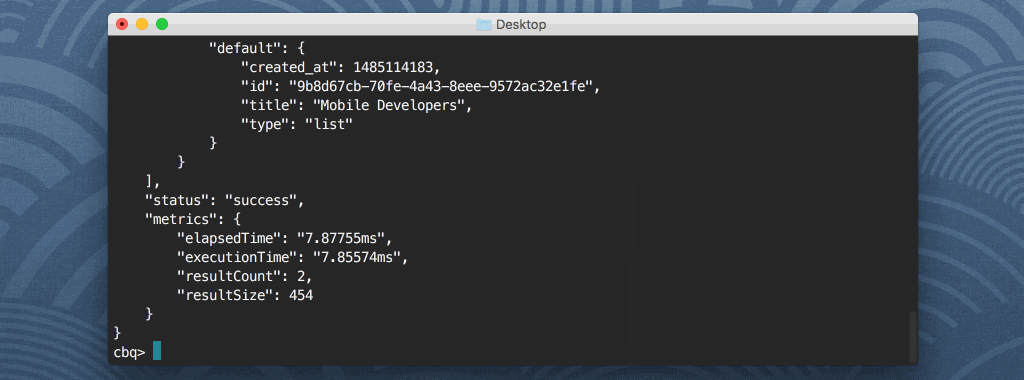
The shell client is similar to what you’d find in MongoDB or any of the relational database technologies. What if you wanted to save your query results to a file, rather than display them in the shell? You might do something like this:
|
1 |
echo "SELECT * FROM default;" | /Applications/Couchbase Server.app/Contents/Resources/couchbase-core/bin/cbq -u Administrator -p password -o ~/Desktop/output.txt |
You’re not limited to strictly query execution with CBQ. There are connection and security management features that are also available. A full feature set can be seen in the documentation as well as this blog post I had written previously.
Query Workbench and CBQ both have their purpose, but in most cases you’ll be querying your documents using one of the many developer SDKs within your application. With language support for popular developer technologies such as Java, .NET, Node.js, and Golang, you’re fully covered when it comes to using NoSQL within your application.
Indexing in Couchbase Server
Querying Couchbase requires indexes to be created within your Couchbase cluster. There are a few types of indexes that can be created, and they are done so based on your application needs.
Take for example the local index. When local indexes are created in the cluster, each node indexes the data it holds locally. This is a solution that works well for a single node deployment, but as you start to increase the node count in the cluster, the query latency begins to suffer. This is because scatter gather has to happen between the available nodes before returning the data back to the client.
As you create a multi-node cluster, it makes more sense to start using global secondary indexes (GSI). In this scenario, the index is placed away from the data nodes and exists in fewer quantities. Instead of using scatter gather on each local index, the query goes against the global index which knows the data we want and then returns it. This significantly improves the query latency.
So how do you create a global secondary index on your cluster? Try executing something like the following:
|
1 |
CREATE INDEX people ON default(firstname, lastname) WHERE type = "person" USING GSI; |
Both local indexes and global secondary indexes can be read about in a great post on the blog.
This brings us to one of the newer indexing features of Couchbase. As of Couchbase 4.5, there are what are known as memory optimized global secondary indexes (MOI).
Now instead of indexes existing on disk and running at disk speeds, they can now exist in memory at much greater performance. More information on memory optimized indexes can be read about in this blog post.
So how do you know what indexes your queries are using? It makes sense to run an EXPLAIN on one of your queries:
|
1 |
EXPLAIN SELECT firstname, lastname FROM default WHERE type = "person"; |
The results on the EXPLAIN tell which index the query used as well as various metric information about what was done in the process. If using the index I created for this query, the EXPLAIN should say that we are using the people index.
Production-Ready with a Powerful Customer Backing
Both Couchbase Community and Enterprise Edition are production-ready and actively being used by well known organizations. Get ready for some name drops.
Enormous and highly respected companies such as, but not limited to, LinkedIn, PayPal, eBay, United, Marriott, GE, and Verizon are using thousands of Couchbase nodes to power the data layer of their organization. Some of these companies have spoken at Couchbase Connect and recordings can be watched via YouTube.
For a list of more Couchbase customers, check out the list here.
Conclusion
Couchbase is a feature rich NoSQL document database that is most certainly production ready. With the ability to use a flexible JSON data model and advanced querying and tooling, Couchbase becomes a perfect database for almost any scenario.
For more information on using Couchbase, check out the Couchbase Developer Portal for tutorials and other documentation.