
Since the GA back in Nov 2018, Couchbase Analytics is being used in multiple verticals for rapid time to insight – ad-hoc analysis by a payment provider, shopping cart analysis by an e-tailer, next gen ticket booking engine by a global airline, real-time movement of food carts inside a baseball stadium as fans fill it up – and many more.
In the initial release, one of the design goals of the system was the availability of the Analytics service to run queries even when rebalance, failover, or rollback operations were being performed on a cluster. As a result, the Analytics service would return query results even when data was being moved or re-partitioned. This design was tailored for developer productivity and enabled DevOps teams to independently rebalance, failover or rollback a Couchbase cluster.
As customers have rolled out Analytics in production, a common request is to ensure that non-monotonic results are not returned. Non-monotonic behavior is when a query that is evaluated at a certain time C returns a result that was current back at time A, a much earlier point in time, with intervening queries having returned more recent results. The figure below illustrates the concept.
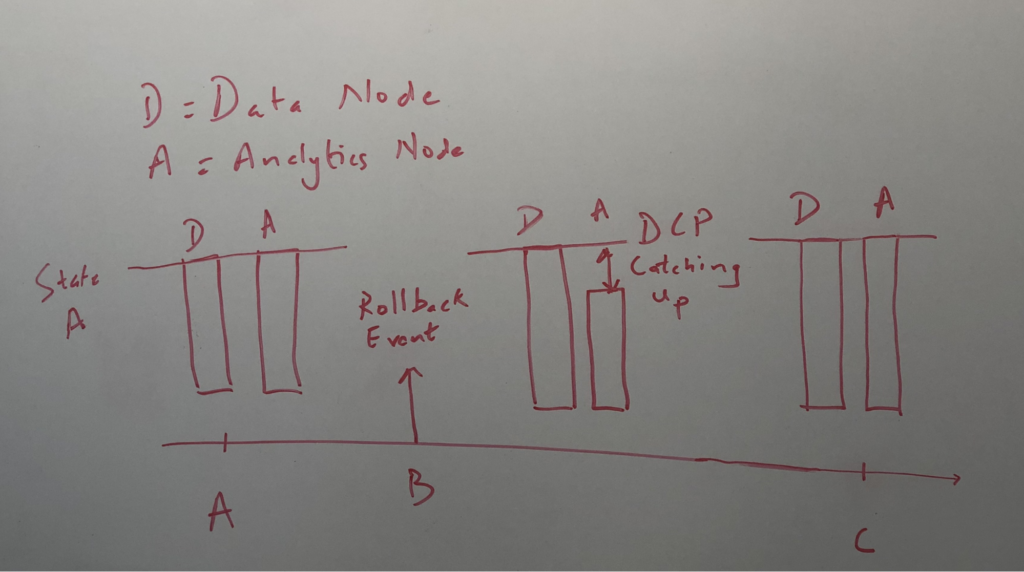
This is especially true for customers running business-critical applications on Couchbase like consumer spending, sales per quarter, items in the shopping cart, inventory etc. Customers don’t want reports, dashboards, analysis and consequently the insights to be affected by cluster operations while running such business-critical applications.
To ensure that future queries will only return once the ingestion of data into Analytics is back to the state where queries were run previously, we are introducing “scan consistency” in the upcoming release.
Scan consistency refers to the fact that the data in the Analytics service is consistent with the state of data in the data service.
The goal of scan consistency is to avoid non-monotonic behavior by not returning query results before a previously valid state is reached once again.
To do this, all you need to do is to set the appropriate preferences in the query workbench. I’ve attached a screenshot below with the preference “scan consistency” set to either of the following:
- not_bounded
- request_plus

not_bounded (default):
Similar to the behaviour in 6.0, the query will be immediately evaluated based on the current data that has been ingested (or re-ingested in the event of a significant rollback).
request_plus:
Before executing the query, the datasets that are needed to answer the query will be identified and Analytics will retrieve the current state of the buckets from the data nodes feeding those datasets. The query will not be executed until the datasets have ingested all the data up to the bucket’s state when the query request was received.
Optionally, you can also specify the amount of time to wait before a query times out using the “scan_wait” parameter.
A request_plus query with a scan_wait parameter setting will time out if the requested level of scan consistency is not achieved within the time specified.
Resources
Download
Documentation
Couchbase Server 6.5 Release Notes
Couchbase Server 6.5 What’s New
Blogs
Blog: Announcing Couchbase Server 6.5 – What’s New and Improved
Blog: Couchbase brings Distributed Multi-document ACID Transactions to NoSQL