
A lot has already been said about microservices over the last few years, but I commonly see new distributed systems being developed with the old mindset of monoliths. The side effect of building something new without the understanding of some key concepts is that you will end up with more problems than before, which is definitely not the goal you had in mind.
In this article, I would like to tackle some concepts that we historically take for granted and which might lead to poor architecture when applied to microservices:
Make Synchronous Calls Only
In a monolith architecture, we are used to All-Or-Nothing availability, we can always call any service anytime. However, in a microservices world, there are no guarantees that a service on which we depend will be online. It could be even worse, as a slow service can potentially slow down the whole system as each thread will be locked for a certain amount of time while waiting for the response of the external service.
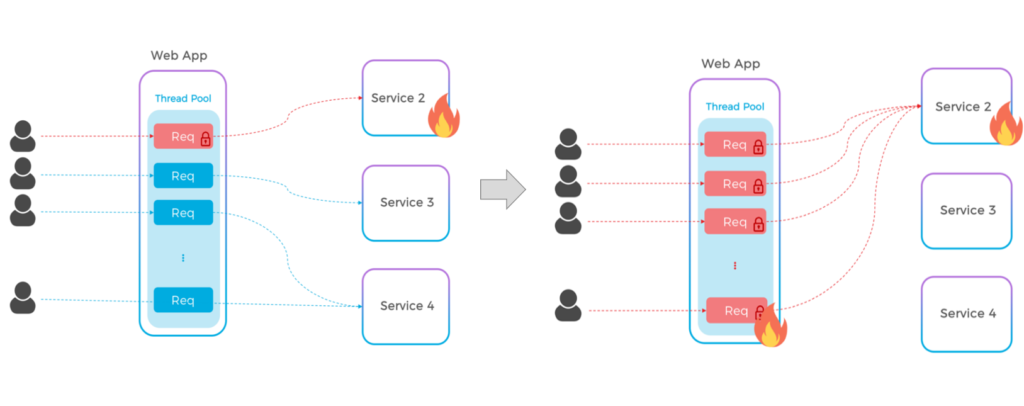
How locked/slow threads eventually consumes your entire thread pool
We are still learning how to properly implement communications between services, but the rule of thumb is to make everything asynchronous, and that is where one of the first challenges emerges, because historically we haven’t exercised enough our ability to transform a synchronous flow into asynchronous.
Hopefully, most of the use cases can be implemented asynchronously with the right amount of effort. Amazon, for instance, implemented its whole order system that way, and you barely feel it. They will almost certainly let you place an order successfully, but if there is any problem with the payment or if the product is out of stock, you will receive an email notification a few minutes or hours later telling you about it and which actions need to be taken. The advantage of this approach is clear; even if the payment or stock service is down, it won’t block users from placing an order. That is the beauty of asynchronous communication.
Of course, not everything in your system can be async, and to deal with the common problems of synchronous calls like network instability, high latency or temporary unavailability of services, we had to come up with a set of patterns to avoid cascading failures such as local caches, timeouts, retries, circuit breakers, bulkheads, etc. There are many frameworks out there implementing those concepts, but the Netflix Hystrix is currently the most well-known library.
There is nothing essentially wrong with this approach; it works pretty well for several companies. The only downside is that we are pushing an extra responsibility for each service, which makes your microservice even less “micro”. Some options have been proposed in the last two years to address this issue. The Service Mesh pattern, for instance, tries to externalize this complexity in a form of a sidecar container :
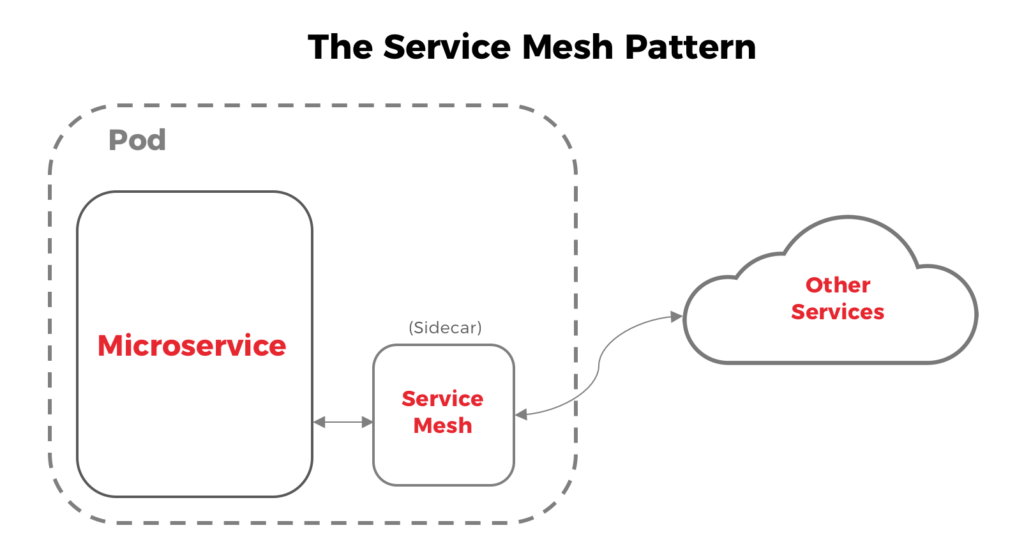
I personally like this approach, especially because it is language agnostic, which means that It will work for all of your microservices regardless of the language in which it is written. Another advantage is the standardized metrics, as different libraries/frameworks might use a slightly different algorithm for retries, timeouts, circuit breaks, etc. Those small differences might impact significantly the generated metrics, making impossible to have a reliable vision of the system’s behavior.
UPDATE: If you want to read more about the Service Mesh pattern, check out this excellent presentation.

In Summary, thinking about how services will communicate with each other is essential for a successful architecture, and should be planned ahead to avoid a chain of dependencies. The less the services know about each other, the better the architecture is.
Just Use RDBMS for Everything
After a 30-year monopoly of RDBMS, it is understandable why many people still think that way. However, nowadays, virtually every day a new database is born (and two JavaScript frameworks). If in the old days, picking a database was a matter of choosing one among five, today, the same task demands much more attention.
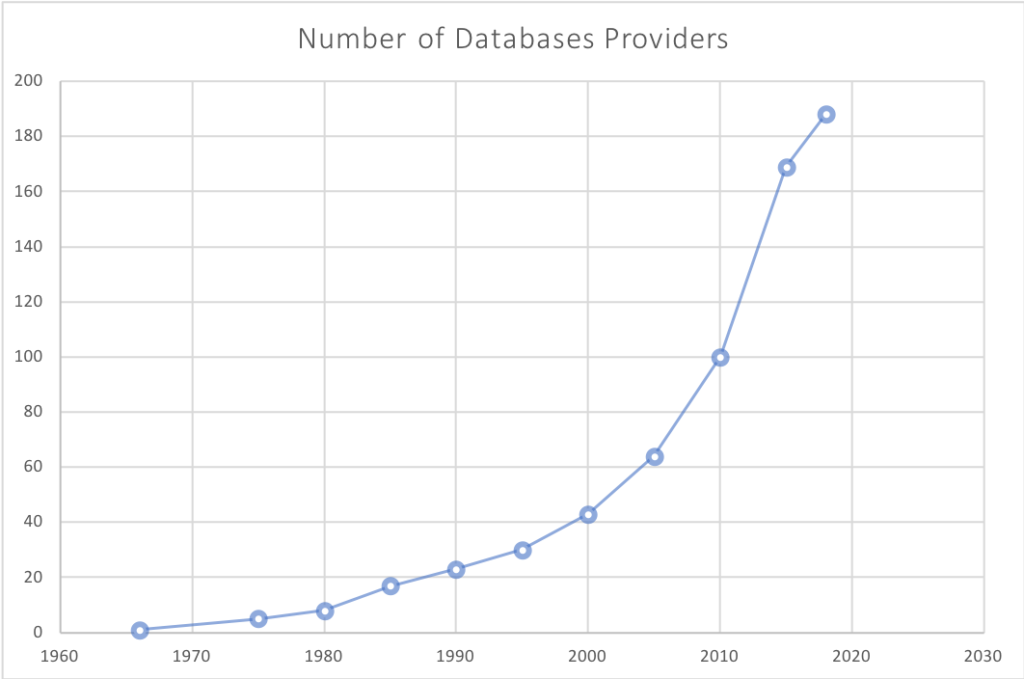
Source: db-engines.com – initial release dates
As Martin Fowler said 12 years ago, there are a lot of benefits on choosing a specialized storage, such as: higher performance, lower cost, etc. I won’t spend your time going through all the downsides of RDBMS (slow reads, sparse data, impedance mismatch, joins, etc). Rather, I would just like to highlight again how the database plays a major role in the overall performance of the system, and an inappropriate choice will eventually cost you much more money.
The benefits of polyglot persistence are crystal clear, and the maturity of the solutions have been proven by numerous successful critical use cases, just to name a few: Pokémon Go, AirBnB, Viber, eBay, Sky, Amadeus, Amazon, Google, LinkedIn and Netflix
I would have agreed five years ago with the “learning curve argument” of why you have not started with NoSQL yet. Nonetheless, since then, a lot has changed, and some companies have put a lot of effort on making it really easy for developers and DBAs, like the Couchbase Spring Boot/Spring Data support or the recently launched Kubernetes Operator which aims to automate most of the DBAs work.
Don’t think about Debugging and Observability
One day, you will eventually have a distributed bug which spreads inconsistencies on your whole system. Then, you realize that there is no easy way to understand where things are failing: Was it a bug? Was it a network issue? Was the service temporarily unavailable?
That’s is why you have to plan in advance how are you going debug your system. Hopefully, for networking a Service Mesh might be a quick fix, and for distributed logging, tools like FluentD or Logstash are handy. But, when we talk about understanding how an entity reached a specific state, or even how to correlate data between services, there is no easy tool out there.
To address this issue, you can use Event Sourcing/Logging. In this pattern, each service stores (and validates) all changes to the state of the application in an event object, and naturally, whenever you need to check what happened with a particular entity, all you need to do is navigate through all the log of events related to it.
If you also add versioning to your state, fixing inconsistencies will be even easier now, as you will have the ability to fix the inconsistent messages by just setting the state of the object to what it was before, and then replay all messages received from the problematic one onwards.
Both versioning and logging can be done asynchronously, and you probably won’t query this data often, which makes it a cheap in-house solution for debugging/auditing your system. I will post next week a deep dive on this pattern, so hold on for a week.
There are many other frameworks/patterns to help you debug your microservices, but they all usually demand a single distributed strategy in order to work. Unfortunately, the moment you realize that you need such a thing, it is already too late and you will need to spend a significant amount of time refactoring the whole thing. That is one of the main reasons why you need to define how are you going to observe/debug your system before even start.
If you have any questions, feel free to tweet me at @deniswsrosa