
The birth of BCBS 239
This blog examines the principles of BCBS 239 strictly thru the technology perspective and how NoSQL is relevant in the world of compliance in the financial industry and.
But before we dive into that here is a history of regulatory compliance and why it has become so important.
Anyone who lived through the financial crisis in 2007/2008 and saw their 401k portfolios tank to rock bottom levels and see their homes valued at the price of a bag of popcorn already know what I am talking about and know the history behind the regulatory compliance rules that banks have to adhere to and the scrutiny that they are being continuously subjected to. It is believed that the financial crisis in 2007/2008 happened because banks were not able to effectively report risk causing a huge breakdown leading the crisis. BCBS 239 is a set of principles set forth by the government agencies to strengthen bank’s risk aggregation and risk reporting practices.
It was believed by the powers to be that
- The inability of the IT infrastructure and data architecture to be able to support the management and governance of Risk lead to the crisis. Many banks were unable to manage risks because of poor risk aggregation severely limiting their ability to accurately report risk exposure information in a timely fashion
- That by Improving decision making capabilities by enhancing management of information across legal entities the crisis can be averted from happening again. This includes the ability to Improve the speed at which information is available
- These principles would complement other efforts to improve the effectiveness of risk management and assess capital adequacy.
This article does not delve into the intricacies of the principles put forth in BCBS 239 the goal is to really focus on how technology plays a huge part in making this effort successful.
So why can’t banks efficiently manage risk reporting
If you look at the way any business runs today new trading desks mushroom frequently and the banks are under tremendous pressure to quickly get up and running with these new legal entities. So there is really no time implement these systems the right way : as in have a centralized data store that has one single version of the truth where enhancements and/or changes are well deliberated before being executed. So given this scenario supporting business units just come up with independent data stores and extract the data and build their own repository so it does not disrupt other business units.
They cannot simply wait for the ideal IT infrastructure to be in place before they introduce a new product or business unit. And in today’s world of mergers and acquisitions there is no time to really fully integrate systems. So silos are here to stay. Any effort to integrate data is a multi-year and multi-million-dollar effort which is a mission impossible to put it politely.
The IT perspective
When you look at this problem from the other side of the fence ie from the IT perspective it is expected to move at the speed of business and deliver results. IT does not get credit for building a beautiful engineering system that seamlessly integrates data and have dashboards update with the latest and greatest information. There is no time to adhere to the SDLC and waterfall development methodology. AGILE is the new way to develop systems as they have business riding their backs to quickly see value from every penny spent on IT projects.
The pressure on IT is immense and they are the backbone of this regulatory onslaught. Data integration and unification is not an overnight task and usually involves months/years of planning so even if there is budget available to do this the success of such a project is very open ended.
Some reality checks…..
Some things that we have to deal with is the fact that data silos are here to stay and any strategy we use has to work around it. Fortunately thanks to advances in technology and how they leverage HW and SW there are sections of this problem that can be easily and effectively resolved
The typical architecture of any firm looks like this. I am not representing the entities or Bus within a bank all I want to represent very loosely is how data flows between different systems and how it gets transformed and consumed. Each box with multiple databases represent data pertaining to a business unit or function within a firm. This is a very simplistic view; in real life the data flow looks more complicated than an intricately woven spider web. The consumers of the data represented in the outer circle can cherry pick any slice of data from any stage in the data transformation life cycle and create their own repository for reporting. So depending on which user you ask; the same question could yield different/ conflicting answers. And this is really the crux of the issue.
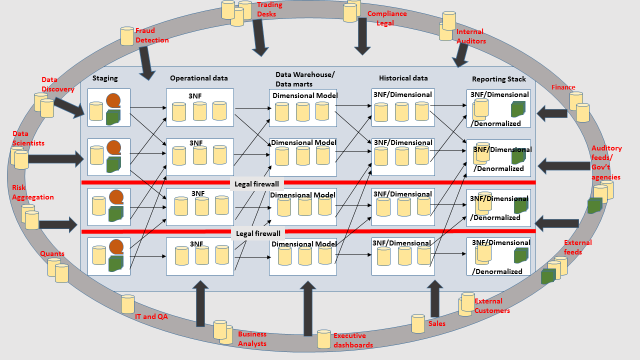
The point I am trying to convey in this overly simplified picture is that
- Data is spread all over the place and each database has its own unique structure built to provide maximum performance and flexibility to its users. So something can go from raw files to 3NF to dimensional models (star and snowflake) back to de-normalized format for ease of use.
- When somebody starts a new initiative. He/she would prefer pulling data out of existing systems and creating their own repository of data to play around with so they don’t step on anybody’s toes.
- There are several redundant/ ungoverned copies of data residing in different areas and each copy is a different version of the original copy making it very difficult to compare and correct data
- The veracity of any report cannot be verified because depending on where it comes from the information can be conflicting.
The data mart centric approach allows IT to move at the speed of business. We could stay up all night long and come up with million reasons on why everything needs to be integrated and how having a single copy of data is the best way to do this, unfortunately data-silos equals moving with the speed of business.
Some Quick Wins with Couchbase
As stated in the first section a lot of change needs to happen so banks are able to assess capital adequacy and mitigate risk.
If I were to quickly sum this up the two key things that come to my mind is that this specific problem is mostly
- A structured data problem (Thank you God!) however schema needs to still tolerate a lot of changes and react quickly.
- Data integration issue as it needs to be aggregated and served up in a fast, highly available fashion
Some low hanging fruits to help in the overall risk mitigation process and without making major disruptive changes to the data capture and applications responsible for providing this information
Data integration: Couchbase server could be used as the platform of choice for landing the data from different silos in a company and quickly aggregating them on the server. Usually the amount of data that need to be aggregated do not run in the petabyte range. It is mostly in the high GB range and the consumers of this data are usually tracking behavior over the last month to understand the risk exposure on any given day.
Quality of Risk reporting: While Couchbase server is not a data quality assessment tool its flexible schema just makes it easy to correct any errors detected by data quality tools and QA processes that will be otherwise limited because of schema rigidity. Eg : if you forgot to include a column or something is breaking because of a change in the data type, you could get up and running very quickly with a solution like Couchbase
Availability of Risk reporting: Couchbase server is memory centric with built in availability features which ensures data is always available
Dashboards: The requirement for dash boards is that they have to be available 24/7/365 to follow the sun, support a wide variety of reporting tools, provide a consistent and dependable view of the state of affairs. While having a robust highly available does not solve the data quality issues but having something available 24/7 and resilient to change will help detect any pipe leaks to be visible and corrected quickly. Having the dash boards from one single platform is also very useful.
Couchbase server is very versatile and has a wide variety of uses in the enterprise. Please refer to my previous article on identifying applications suited to NoSQL databases https://www.couchbase.com/blog/immediate-or-eventual-persistence/
For a better understanding of Couchbase Server architecture refer to the following link http://www.couchbase.com/nosql-databases/couchbase-serve/r
_____________________________________________________________________________________
This article has been written by Sandhya Krishnamurthy, Senior Solutions Engineer at Couchbase, a leading provider of NoSQL databases.
Contact the author at sandhya.krishnamurthy@couchbase.com
- Talk to us at Forums
- Follow us @couchbasedev and @couchbase
Visit the sites below to learn more about Couchbase products, for free product downloads and free training
http://www.couchbase.com/nosql-databases/downloads/
http://training.couchbase.com/online