
Hello everyone! I’m Koji, a Solutions Engineer working in Japan. This is my first post under couchbase.com and I’m really excited about it!
In this blog, I’m going to explain how you can integrate Couchbase Server with Apache NiFi.
Table of Contents:
-
Couchbase Server Connection setting: CouchbaseClusterService
-
GetCouchbaseKey example: Download specific Couchbase docs as a single Zip file
What is NiFi
Apache NiFi is a top-level Apache project that supports powerful and scalable directed graphs of data routing, transformation, and system mediation logic. Recently, Hortonworks announced that they provide Hortonworks DataFlow (HDF). NiFi is used in HDF as a core data flow processing engine in order to support IoAT (Internet of Anything) use cases. Please look at those links for further information.
NiFi, Couchbase, and Me
My official title at Couchbase is ‘Solutions Engineer’, and pre-sales is my main task. However, I love to write code, too. Writing code keeps my tech knowledge fresh, which ultimately helps me provide our customers better solutions.
A few days ago, a set of NiFi processors for Couchbase Server access was added into Nifi’s codebase. The contribution was made by ME! It was a great experience working with NiFi committers through the detailed review processes. The comprehensive developer guide documentation really helped me to get into the project.
In case you’re interested in how the contribution process worked, here are some links to look at:
-
Pull Request: NIFI-992: Adding nifi-couchbase-bundle
Ok, enough introduction. Let’s dive into NiFi configurations to describe how to integrate Couchbase Server!
NiFi key components
After downloading NiFi, you can start it and access the GUI data flow designer via your browser. Here are some key components you should be familiar with:
-
FlowFile: Every piece of data streamed within NiFi flow is transferred as an object called a FlowFile. It has opaque contents and an arbitrary set of attributes. Yes, it looks like a file indeed.
-
Processor: A small processing module that is supposed to be good at a single task, sort of like a Linux command. There are about 80 processors available as of today. They perform functions such as handling files, accessing databases, and handling HTTP and other protocols.
-
Relationship: Each processors is connected by a pipe called a Relationship. Some processors have multiple relationship like success, failure or original. The processed FlowFile will be transferred to the next processor via this relationship.
Organize Data Flows by Process Group
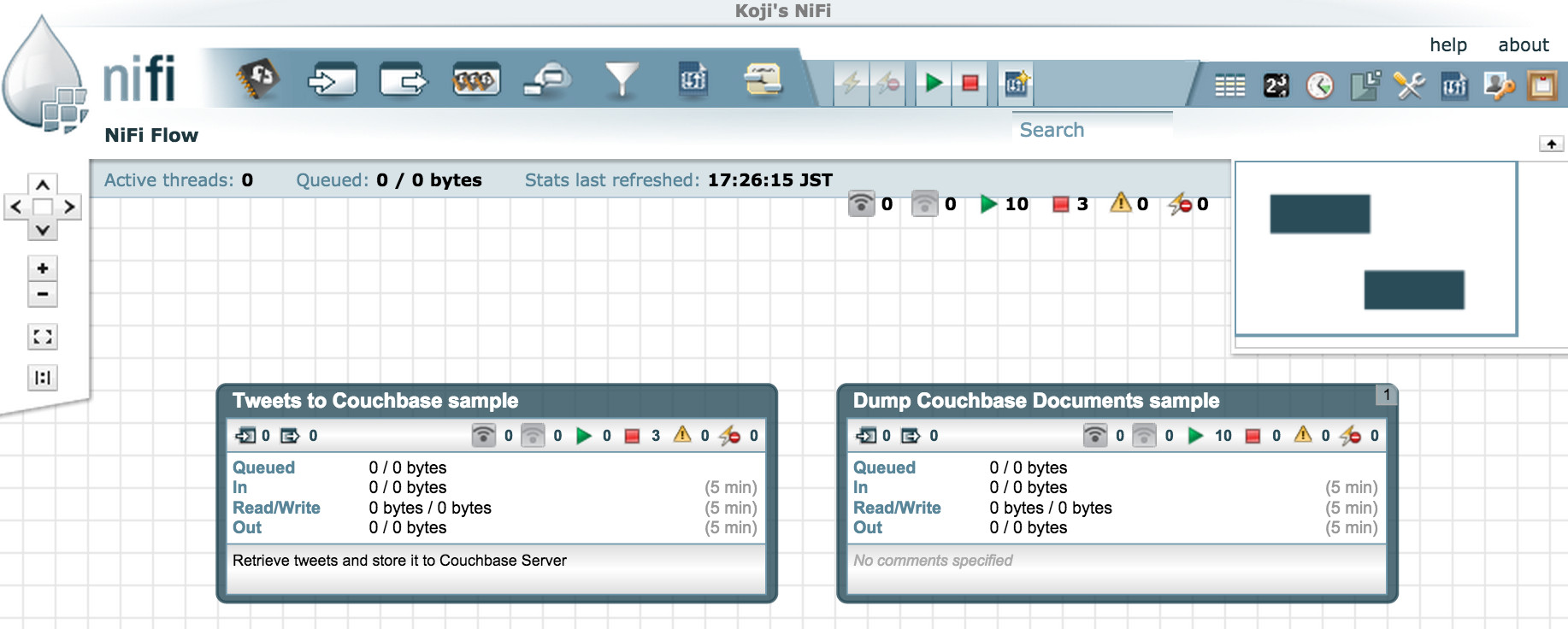
In NiFi Data Flow, a “Process Group” can be really handy when the flow get more complex. It allows you to organize multiple flows, then each Process Group can be started/stopped individually. In this demo data flow, I set up two Process Groups, “Tweets to Couchbase sample” and “Dump Couchbase Documents sample”.
Couchbase Server Connection setting: CouchbaseClusterService
Let me describe how to configure a connection to a Couchbase Server cluster.
Within a realistic NiFi Data Flow, you will have to use Couchbase processors multiple times in order to put and get data from the cluster. So, it wouldn’t be a good idea to configure connection settings at each processor. If you did that, it would be hard to change the target cluster because the cluster settings would be scattered all over.
To avoid this problem, NiFi provides a mechanism called ControllerService to configure a central component that can be shared among processors. NiFi includes some existing Controller Services such as the one that provides connection pooling to an RDBMS. So I followed the design and implemented CouchbaseClusterService.
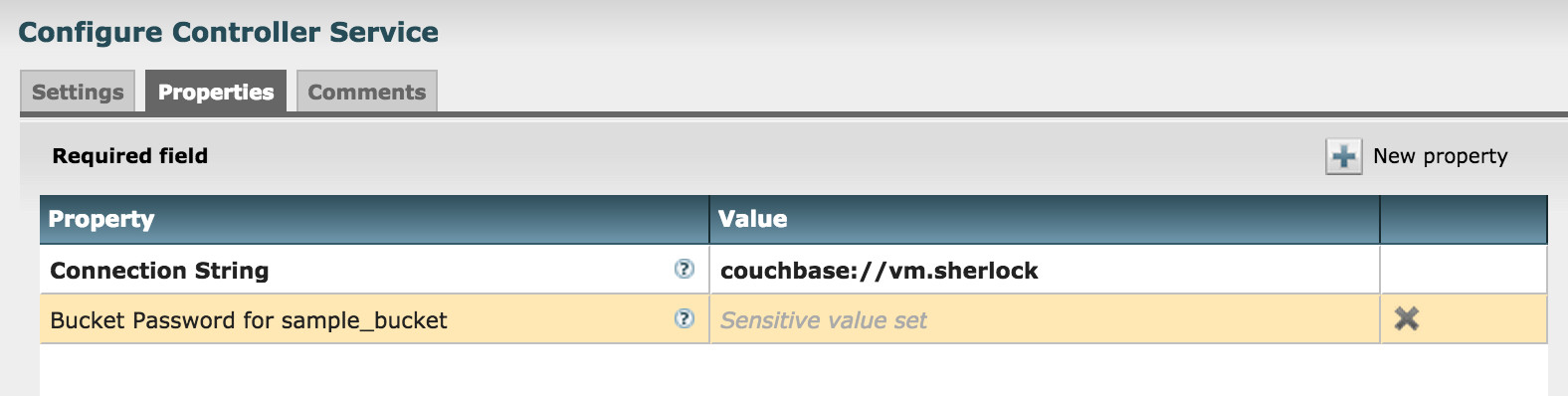
It allows you to set the Connection String to specify which Couchbase Server cluster to access. If buckets require a password, you can set it here, too. NiFi configuration has two types of properties, static and dynamic. “Connection String” is a static one, and “Bucket Password for {bucket_name}” is dynamic. You can add new Dynamic Property settings by clicking “New property” button to specify passwords for different buckets.
So, again the important thing is, all of the cluster level configuration is managed by this CouchbaseClusterService. If you’d like to work with another Couchbase cluster, then you simply add another CouchbaseClusterService and configure it appropriately.
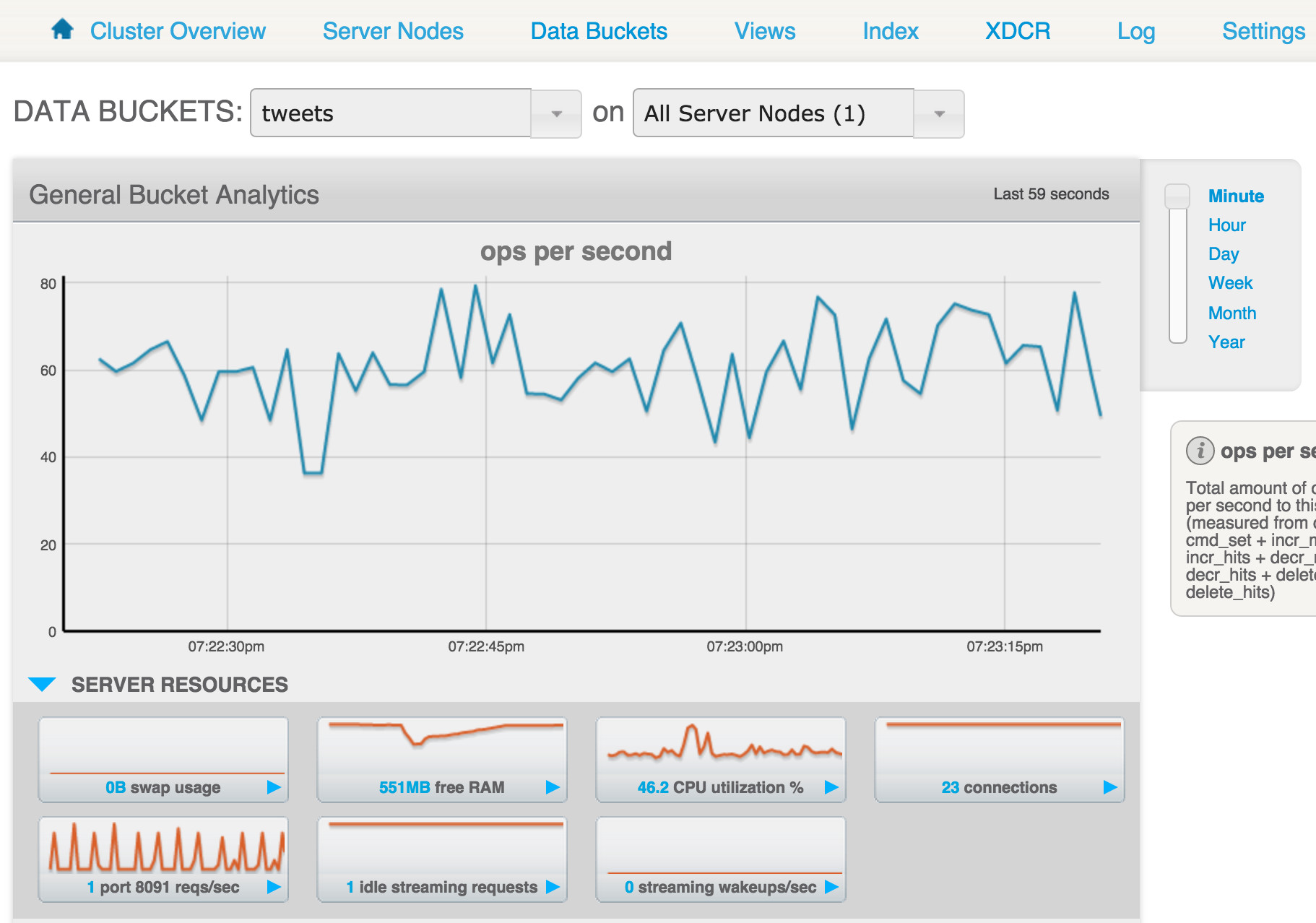
PutCouchbaseKey example: Store Tweets in Couchbase Server
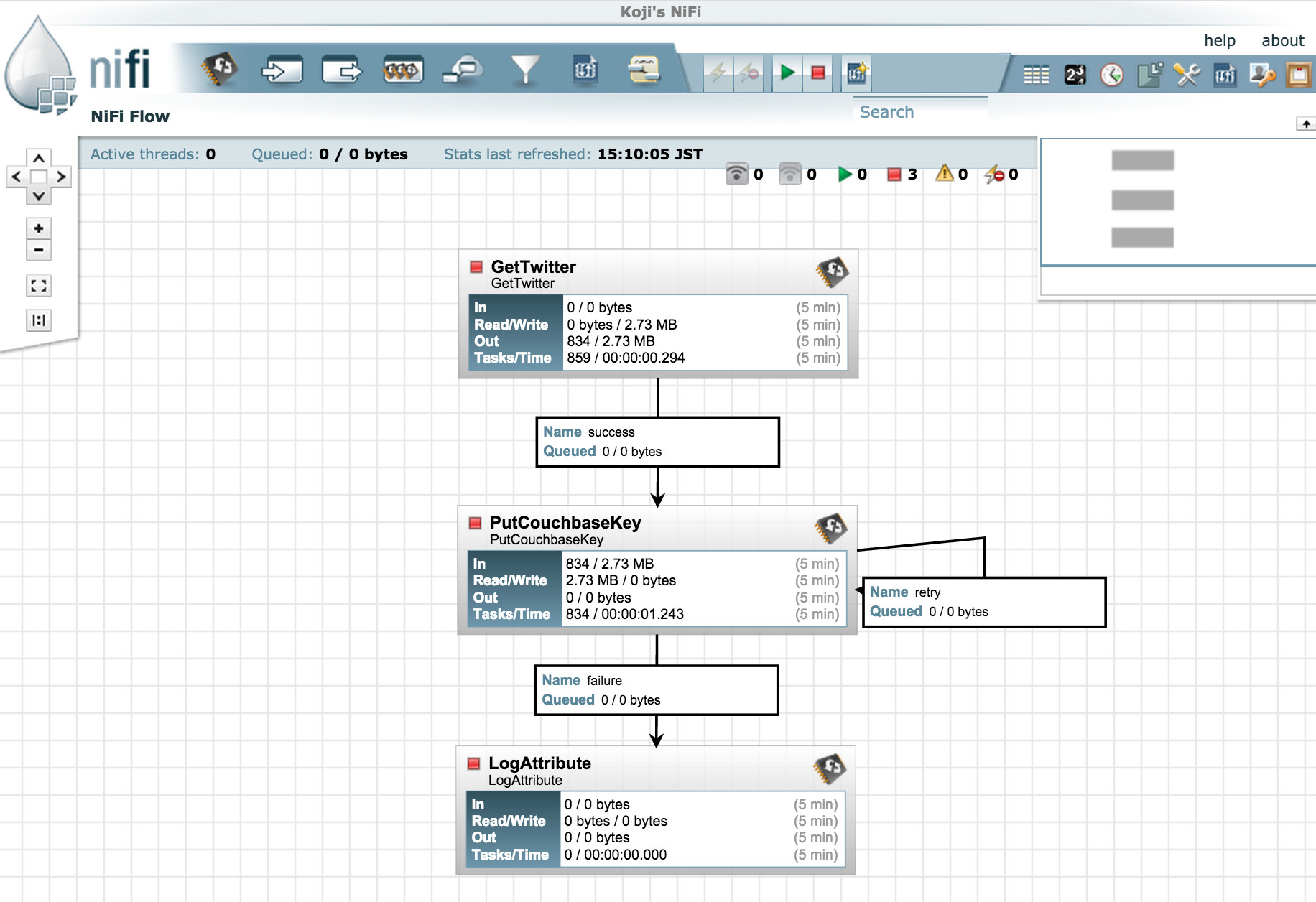
Twitter feed processing is a common example that we can use to illustrate stream data flow. With NiFi and Couchbase, it’s incredibly easy, as shown in the following image:
-
GetTwitter: NiFi has a variety of useful Processors like this, and can easily integrate with other systems.
-
PutCouchbaseKey: Each Tweet is sent as a FlowFile. Here, I store it using FlowFile UUID as the Couchbase document ID. As the image shows, PutCouchbaseKey has a self “retry” relationship. If a FlowFile fails with CouchbaseExceptions and it can be retried, such as might happen with a temporary server-side error, then transfer it to the “retry” relationship. If the error isn’t recoverable, such as mis-configuration or some other hard error, then those FlowFiles are transferred to the “failure” relationship.
-
LogAttibute: I added a LogAttribute processor at the end of the flow.The LogAttribute can output log messages about a FlowFile’s properties and contents. This is handy for debugging any issues that may arise.
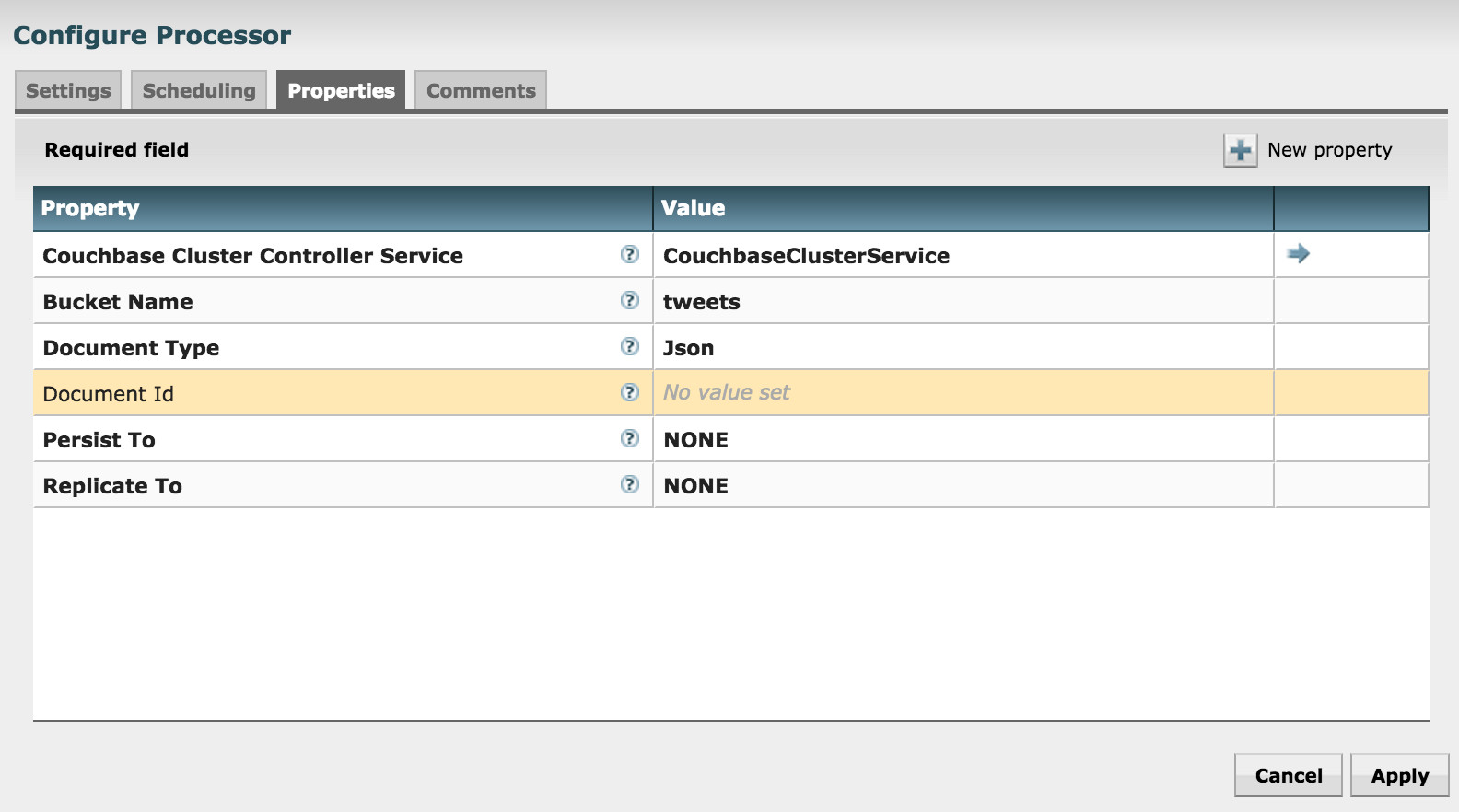
Let’s look at the PutCouchbaseKey configuration:
-
Couchbase Cluster Controller Service refers to the centralized Couchbase controller service that was described earlier.
-
Bucket Name is the name of bucket you want to store the contents in.
-
Document Type is either Json or Binary.
-
I left the Document Id property blank to let the processor use the FlowFile UUID as the document id. Alternatively, you could specify NiFi Expression Language here to use another property value or to calculate a document id.
Now that we’ve configured the CouchbaseClusterService and Processors, let’s start NiFi Data Flow. The only thing you need to do is push the green triangle button. Then you can confirm that Tweets are being stored in Couchbase!
GetCouchbaseKey example: Download specific Couchbase docs as a single Zip file
You may want to download a particular set of documents from Couchbase Server in order to send them to another system or to make a partial backup.
In order to do that, I’ve configured the data flow like you see in the following image. It’s more complex than the previous Twitter example and uses a few different types of processors:
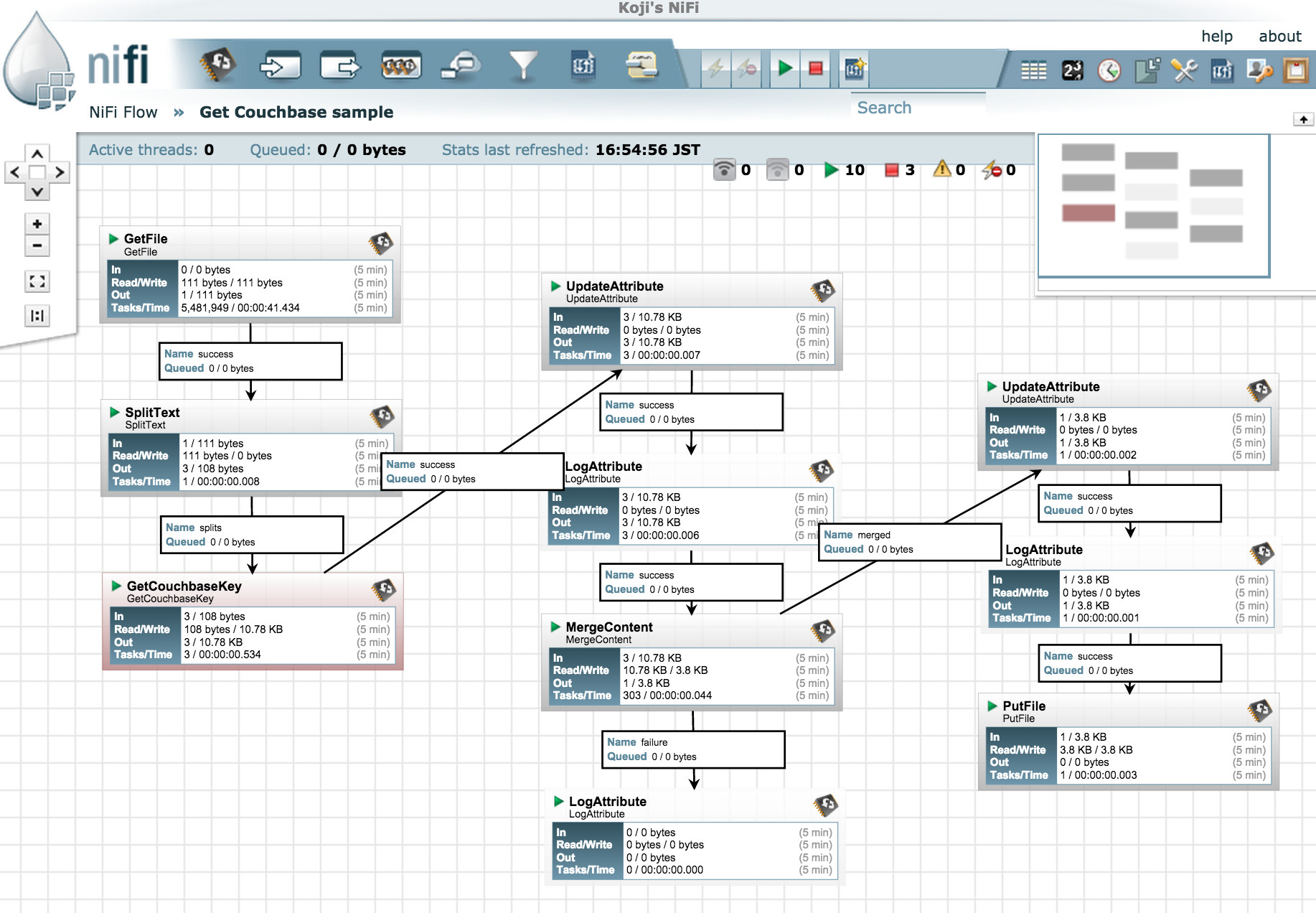
Let me explain what each processor does:
-
GetFile: This watches the specified directory and once target file is put into it, it transfers the contents to the next processor.
-
SplitText: Splits the content in the file and send each line as a FlowFile.
-
GetCouchbaseKey: Gets a document from Couchbase using the incoming FlowFile content as a document id.
-
UpdateAttribute: In order to use Couchbase document id for the actual filename that is used in the final Zip file, I copied “couchbase.doc.id” attribute to “filename” here.
-
MergeContent: Merges and compresses multiple FlowFiles into a single Zip file.
-
UpdateAttribute: Sets the Zip filename to current date, using the expression “${now():format(‘yyyyMMdd_HHmmss’)}.zip”
-
PutFile: Finally, puts the Zip file into the specified directory.
The actual directories and file look like below:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
# Directory and File drwxr-xr-x 2 koji wheel 68B Oct 2 16:19 couchbase-dump-in/ drwxr-xr-x 2 koji wheel 68B Oct 2 16:29 couchbase-dump-out/ -rw-r--r-- 1 koji wheel 111B Oct 2 16:25 in.dat # Specify Couchbase Document Ids to get koji@Kojis-MacBook-Pro:tmp$ cat in.dat 000069ee-cf4d-46bb-a11d-de09a00cd82c 00021100-bb6c-4327-8cad-16474f5cd928 0004b561-1ea4-4e46-8455-2040481d638e # GetFile deletes original file so that it won’t be processed again. # It’s recommended to create the file in different dir, # then put the file into the input dir. # (Optionally, you can keep the original file) koji@Kojis-MacBook-Pro:tmp$ cp in.dat couchbase-dump-in/ # After NiFi processing, a Zip file is created. koji@Kojis-MacBook-Pro:tmp$ ll couchbase-dump-out/ total 8 -rw-r--r-- 1 koji wheel 3.8K Oct 2 16:51 20151002_165136.zip # Extract the Zip file and confirm JSON files are stored in it. koji@Kojis-MacBook-Pro:couchbase-dump-out$ unzip 20151002_165136.zip Archive: 20151002_165136.zip inflating: 000069ee-cf4d-46bb-a11d-de09a00cd82c inflating: 00021100-bb6c-4327-8cad-16474f5cd928 inflating: 0004b561-1ea4-4e46-8455-2040481d638e |
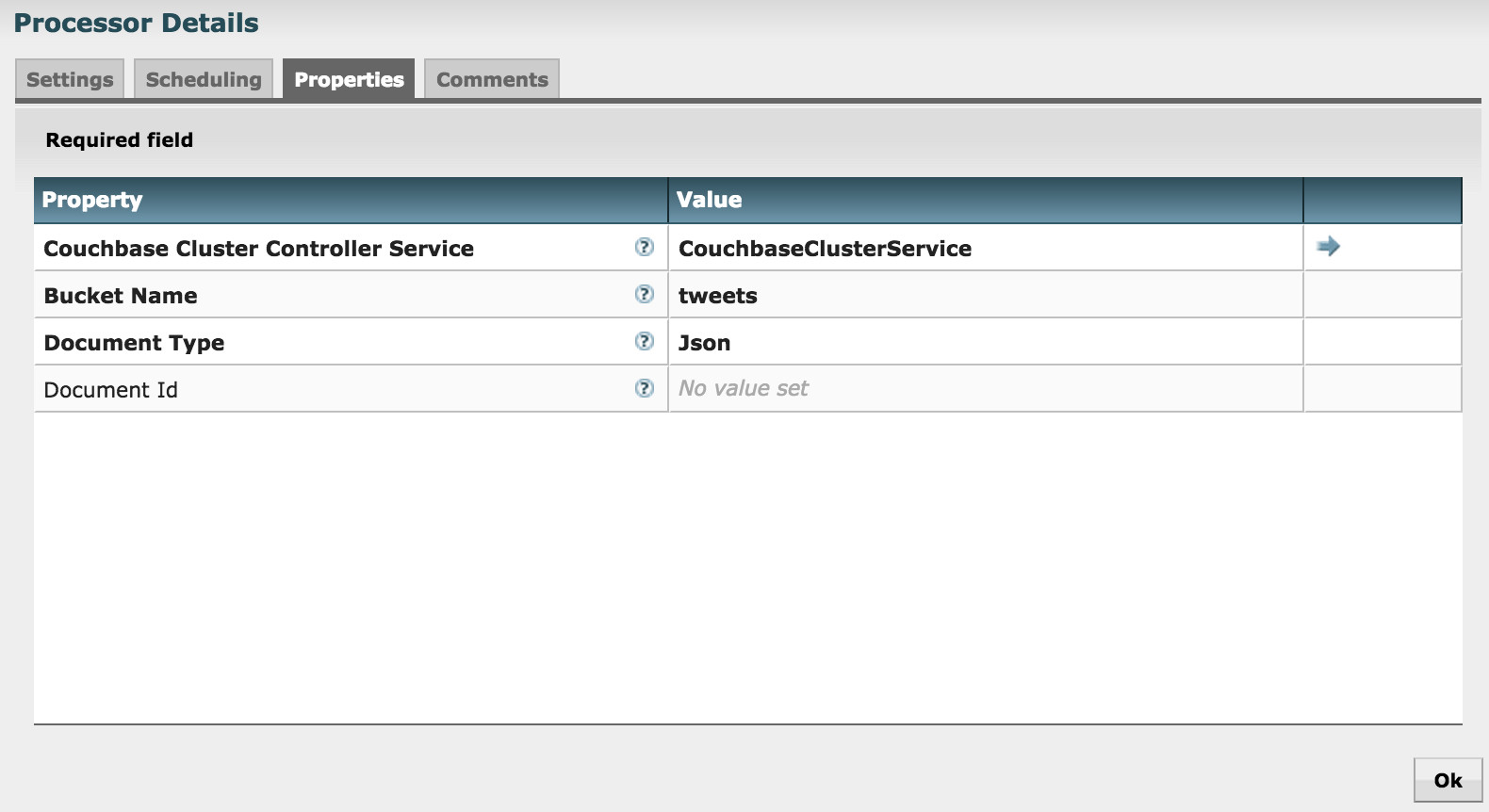
Now let’s take a look at GetCouchbaseKey configuration:
-
Just like PutCouchbaseKey, a connection to Couchbase is configured in ControllerService
-
I left the Document Id blank, to let it use the incoming FlowFile content as document id. You can also specify Expression Language here to construct a document id.
Conclusion
Isn’t it fantastic that you can automate tasks like these without having to write any programs? Although only simple key/value access processors are available at this point, you can use it creatively! I’m planning to add more processors so that you can use View and N1QL queries from NiFi, and I’m looking forward to seeing you again with new functionalities.
Thanks, and happy data processing!