
The purpose of computing is insight, not numbers. — Richard Hamming
The spiral of running the business, analyzing what to change & what to change to, and then changing the business is an eternal one. Do the right analysis, your spiral will get larger. Else, you’ll spiral down.
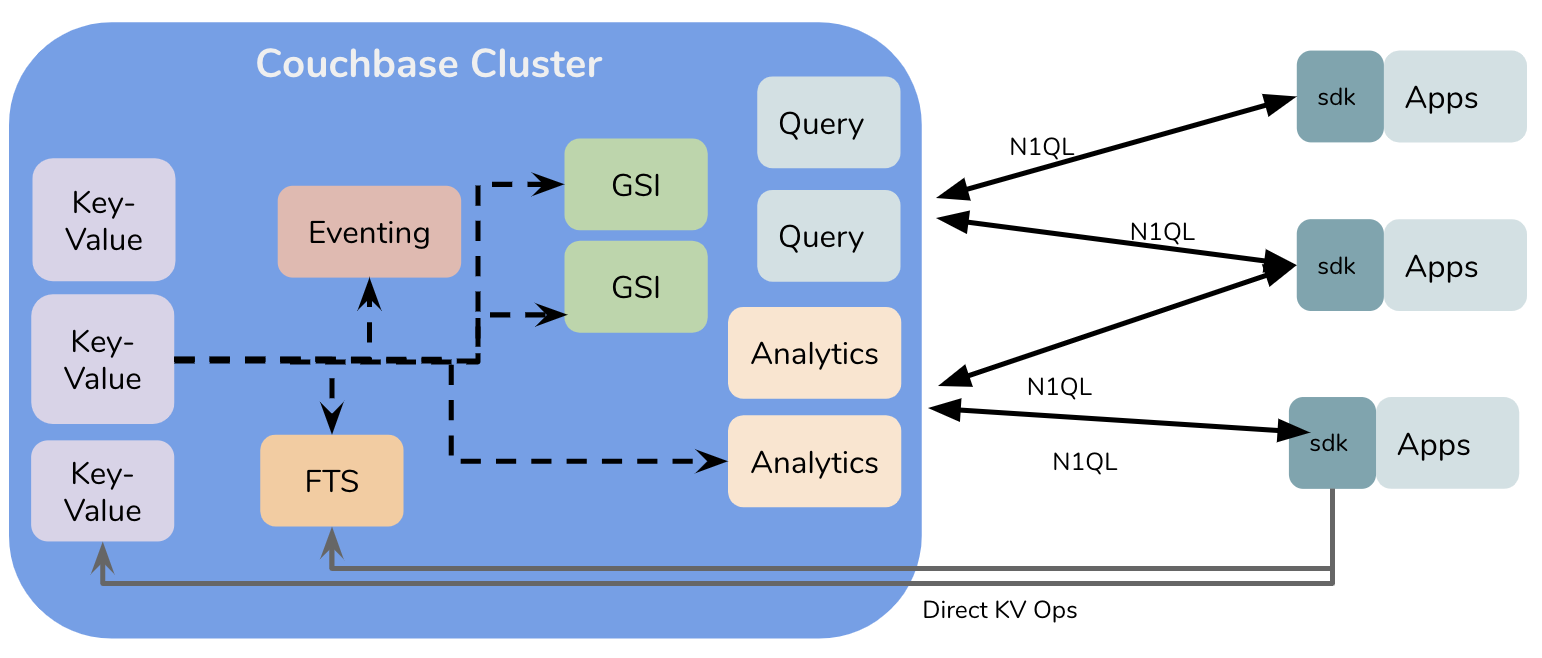
Couchbase, like the other pioneers of NoSQL systems, was created to address extreme scale, performance, and availability requirements of the web 2.0 world. From the simple key-value, Couchbase has evolved to handle query, search and analytics — at scale. Each of them is purpose-built engines integrated via Couchbase’s multi-dimensional architecture. The query and analytics service both talk N1QL. Why build two distinct engines that talk the same language? Because…
One Size Fits All: An Idea Whose Time Has Come and Gone. — Michael Stonebraker
Query engine was built for operational workload and the Analytics engine for the analysis workload. We’ve compared the two engines and given the guidance. MongoDB has followed a similar path from being a clustered database handling simple workload to complex workload for analytics and queries on data lakes.
Last year, MongoDB announced analytic nodes in their clusters for analytic processing. In this blog, we compare and contrast the two engines for the analytics use case.
Couchbase: High-Level Architecture
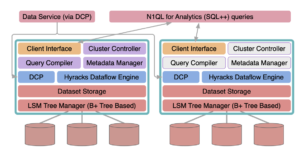
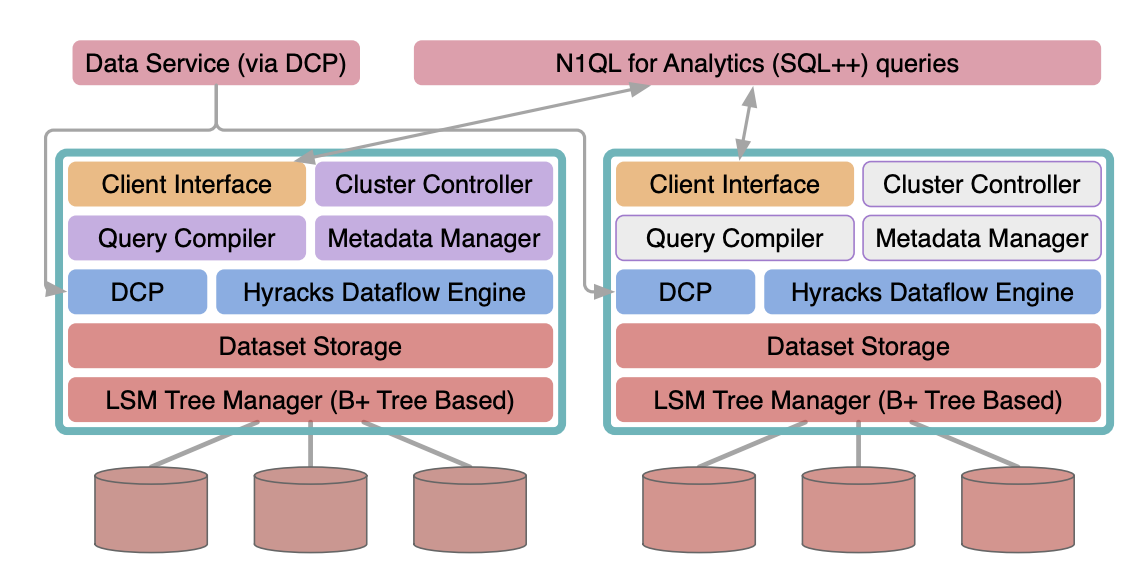
Inside Couchbase Analytics: High-level Architecture
MongoDB Analytics Nodes: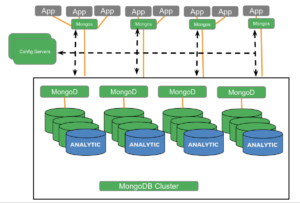
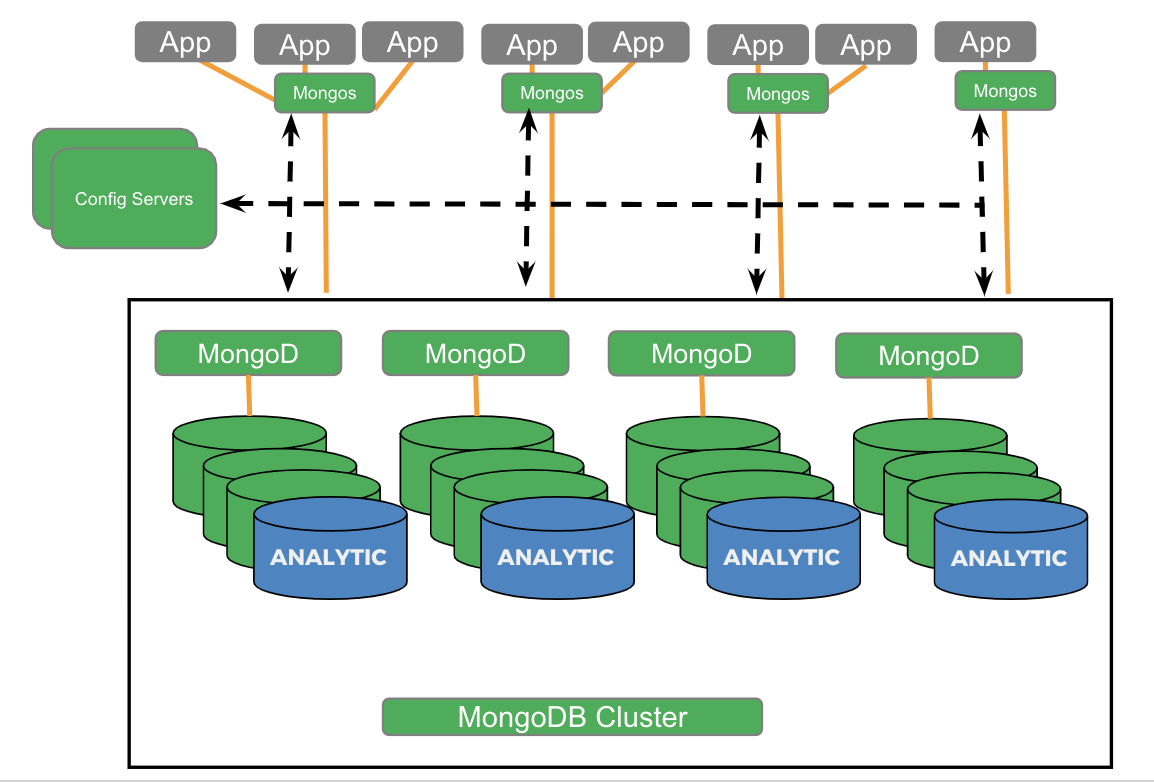
Let’s compare and contrast the analytics support in MongoDB Analytic nodes and Couchbase Analytics.
| MongoDB Analytic nodes | Couchbase Analytics | |
| Docs | https://docs.atlas.mongodb.com/reference/replica-set-tags/ | https://docs.couchbase.com/server/6.5/analytics/introduction.html |
| Architecture | Use a set of Secondary replica nodes with a complete copy of the operational data. The query language is the same (MQL); query processing is the same as the operational workload. | Distinct Analytics nodes which have a user-defined subset of the operational data. The query language is the same (N1QL); query processing is designed for larger datasets (see below). |
| Architecture Details | Atlas Mapped Analytics Nodes | Couchbase Analytics: NoETL for Scalable NoSQL Data Analysis |
| Data Model | BSON | JSON |
| Query Language | MQL – MongoDB Query Language | N1QL – Non 1st Normal-form Query Language; SQL for JSON |
| Query page | MongoDB Query | Analytics Query |
| Query processing | Same as operational query processing, using mongos and mongod for distributed query processing. | Analytics engine designed for massive parallel processing (MPP) of the data. Each N1QL |
| Query optimizer | Shape-Based Optimizer; Requires plan management. | Rule-Based Optimizer. No plan management required. |
| Explain | Text and graphical. | Text and graphical. |
| Indexing | Need to create the index in the operational and have it copied over. | Analytics only Indexing |
| Parallel processing | Each Mongod node runs the basic operations and mongos combines it (e.g. final group and aggregation). | To handle complex analytics queries efficiently, and to deliver
the desired scale-up and speed-up properties, the Analytics Service employs the same kinds of state-of-the-art, shared-nothing MPP (massively parallel processing) based query processing strategies [From the VLDB paper] |
| Indexing | Local indexing | Local indexing |
| Joins – Language | $lookup operator supports simple equality joins between two collections; Only simple scalar fields are allowed. Arrays need to be unwound before joins.
|
INNER JOIN, LEFT OUTER JOIN, NEST and UNNEST operations.
|
| Query processing:data size | Intermediate stages of aggregate() pipeline cannot be more than 100 MiB in size. Query writers/users should use a special flag to allow this. | No Limitations; When the intermediate data (e.g. hash table, sort data) gets bigger, it’s spilled over to the disk. |
| Query processing: Join type | (roughly) LEFT OUTER JOIN | INNER JOIN
LEFT OUTER JOIN |
| Search | Supports search within the query. Uses Atlas search on the cloud and basic B-tree based search on-prem. | Analytics service doesn’t have a built-in search. We need to use query service with FTS for combining search within a query. |
| Queries supported | find() and aggregate() | SELECT statement (from SQL and SQL++) |
| JOIN types (Language) | $lookup — this is roughly LEFT OUTER JOIN via | INNER JOIN
LEFT OUTER JOIN |
| JOIN types (Implementation) |
|
|
| Aggregation | Supports the common grouping and aggregation via aggregate() method. | Supports the common grouping and aggregation via GROUP BY and respective aggregations. See below for Windowed aggregates. |
| Windowed aggregate Functions: Probably, the Coolest SQL Feature. | Unavailable. | Fully supported.
RANK() PERCENT_RANK() DENSERANK() ROW_NUMBER() CUME_DIST() FIRST_VALUE() LAST_VALUE() NTH_VALUE() LEAD() NTILE() RATIO_TO_REPORT() |
| Analyzing data from Multi-clusters | All the data analyzed is from a single MongoDB cluster. | 6.5: All the data analyzed is from a single Couchbase cluster.
6.6: Can ingest and analyze the data from multiple Couchbase clusters. |
| External data | Supports query processing on S3 data. Supports BSON, CSV, TSV, Avro, and Parquet formats. | 6.6: Supports external JSON, CSV and TSV data in S3 |
| External data sources | Supports additional datasources via JDBC driver. Integrated with the aggregation pipeline via, you’ve to wait for it, $sql operator. | None except the ones mentioned above. |
| Subqueries | Subqueries via the aggregation pipeline. | Standard SQL subqueries. |
| Query plan | $explain | EXPLAIN |
| DataViz | Built-in MongoDB charts | No built-in DataViz |
| Business intelligence | Knowi
Tableau and other ODBC, JDBC compliant BI engines. |
Knowi
Tableau and other ODBC, JDBC compliant BI engines. |
References:
- Comparing Two SQL-Based Approaches for Querying JSON: SQL++ and SQL:2016
- SQL to NoSQL – 7 Metrics to Compare Query Language
- Couchbase Analytics: NoETL for Scalable NoSQL Data Analysis