Couchbase Analytics is designed to support ad hoc queries by leveraging efficient parallel processing. This is particularly helpful when the results of one query lead you to seek answers from yet another another query. (For analysts, in other words, all the time!) As with any data platform, these secondary queries can sometimes result in run times significantly different from the first. We recently worked with a customer who saw a noticeable drop in performance after making a small change in his query. The process we went through to isolate and resolve the issue is outlined below.
The Data
As always, the first step in understanding a query is to become familiar with the underlying data. In this case, the data is comprised of JSON documents, each of which is a description of client charges for services. Charges for each session are embedded within an array:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
{ "customer": 1000002, "dtype": "session", "sessionCharges": [ { "qty": 1, "revCode": "B", "svc": 44284, "amt": 40, "svcDate": 1592889276 }, { "qty": 1, "revCode": "A", "svc": 28078, "amt": 24, "svcDate": 1592891076 }, { "qty": 1, "revCode": "B", "svc": 38968, "amt": 26, "svcDate": 1592893416 } ] } |
A couple of notes on the design of the data model:
- They were smart about the fieldnames, which are long enough to be descriptive, but short enough to save space. The fieldnames within the array could easily have been written as “quantity”, “revenueCode”, “service”, “amount”, “serviceDate”. Across 100 million instances, however, this would have required an additional 3.73GB of space before compression.
- They used epoch dates, without milliseconds. If these dates were stored in ISO 8601 format (“2020-07- 24T18:17:49” or with milliseconds “2020-07-24T18:17:49.000”) they would require double the storage footprint.
Initial Query
The initial query was designed to retrieve the highest revenue customer/service combination within each of the revenue code categories:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
select latestService, customer, revCode, service, round(totalDollar) dollars, totalQuant from ( select s.customer, c.svc as service, c.revCode, sum(c.amt) as totalDollar, sum(c.qty) as totalQuant, millis_to_str(max(c.svcDate)*1000, '1111-11-11') as latestService from sessions s unnest s.sessionCharges c group by s.customer, c.revCode, c.svc ) a where rank() over (partition by revCode order by totalDollar desc) = 1 order by revCode, totalDollar; |
A few notes on the query design:
- The array contents are accessed by the “unnest” verb. This allows the values to be aggregated and returned as a flattened record.
- The latest service date is converted from epoch to human-readable date via the millis_to_str() function.
- The window function “rank() over partition” is used in the where clause of the outer query as an efficient means of returning only the top value within each revenue code.
- The round() function is cosmetic, but commonly used in reports where the pennies aren’t significant.
The Slowdown
Problems arose when a volume discount computation (20% off when the cumulative quantity of a service is 10 or more) was added. This new query took six times as long to run!
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
select latestService, customer, revCode, service, round(totalDollar) dollars, round(adjDollar) dollarsAdj, totalQuant from ( select s.customer, c.svc as service, c.revCode, sum(c.amt) as totalDollar, case when sum(c.qty) < 10 then sum(c.amt) else sum(c.amt) * .8 end as adjDollar, sum(c.qty) as totalQuant, millis_to_str(max(c.svcDate)*1000, '1111-11-11') as latestService from sessions s unnest s.sessionCharges c group by s.customer, c.svc, c.revCode ) a where rank() over (partition by revCode order by totalDollar desc) = 1 order by revCode, totalDollar; |
How can we track down the cause of this?
Explain Yourself
The Analytics query console makes it easy to inspect the execution plan for any query, simply by clicking the “Plan” button. Figure (1) below shows the query plan for this query. Don’t worry about the minuscule scale of the diagram; you can use the controls to expand and contract it. You can also click on each individual step for detailed information.
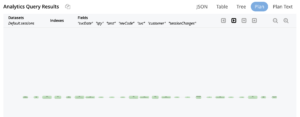
Figure 1
If you prefer, you can also click the “Plan Text” button to generate a JSON document describing the plan:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
{ "operator": "distribute-result", "expressions": [ "$$157" ], "operatorId": "1.1", "physical-operator": "DISTRIBUTE_RESULT", "execution-mode": "PARTITIONED", "inputs": [ { "operator": "exchange", "operatorId": "1.2", "physical-operator": "ONE_TO_ONE_EXCHANGE", "execution-mode": "PARTITIONED", "inputs": [ { "operator": "project", "variables": [ "$$157" ], "operatorId": "1.3", "physical-operator": "STREAM_PROJECT", "execution-mode": "PARTITIONED", "inputs": [ { "operator": "assign", "variables": [ "$$157" ], ... etc. |
This can become very deeply nested (and somewhat difficult to read) as queries become more complex. A trick our engineers often use is to prepend the command “explain text” in front of the query:
|
1 2 3 |
explain text select ... etc.; |
This provides a detailed description of the plan without the squiggly brackets:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
distribute result [$$157] -- DISTRIBUTE_RESULT |PARTITIONED| exchange -- ONE_TO_ONE_EXCHANGE |PARTITIONED| project ([$$157]) -- STREAM_PROJECT |PARTITIONED| assign [$$157] <- [{"latestService": millis-to-local(numeric-multiply($$168, 1000), "1111-11-11"), "customer": $$customer, "revCode": $$revCode, "service": $$svc, "dollars": round($$166), "dollarsAdj": round($$126), "totalQuant": $$167}] -- ASSIGN |PARTITIONED| exchange -- SORT_MERGE_EXCHANGE [$$revCode(ASC), $$166(ASC) ] |PARTITIONED| order (ASC, $$revCode) (ASC, $$166) -- STABLE_SORT [$$revCode(ASC), $$166(ASC)] |PARTITIONED| exchange -- ONE_TO_ONE_EXCHANGE |PARTITIONED| etc. |
This is what we will use to search for clues.
Let’s Make a List
We’re pretty sure that the slowdown was introduced when we added the CASE statement defining field adjDollars, so let’s start by searching for case logic. We find it on line 33:
|
1 |
assign [$$125] <- [switch-case(TRUE, lt($$165, 10), $$117, $$124)] |
As we follow the logic in the lines following, we see the execution plan continuing to assign and exchange variables in a partitioned fashion. On line 44, however we see the following:
|
1 |
aggregate [$$117] <- [listify($$196)] |
In cases where query performance or memory consumption are a concern, the “listify” function can be a red flag. (One engineer jokingly calls it “an evil function”.) It has its uses, particularly in the internal transformation of array aggregates, but it can also be used by the execution plan as the function of last resort. In our case, we see the variable $$117 is the result of this listify process. This $$117, we can see in the switch-case above, is associated with the sum(c.amt) object in the query. So let’s try to move the computation of the sums out of the interior switch case and make them part of a LET:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
explain text select latestService, customer, revCode, service, round(totalDollar) dollars, round(adjDollar) dollarsAdj, totalQuant from ( select s.customer, c.svc as service, c.revCode, totalDollar, case when totalQuant < 10 then totalDollar else totalDollar * .8 end as adjDollar, totalQuant, millis_to_str(max(c.svcDate)*1000, '1111-11-11') as latestService from sessions s unnest s.sessionCharges c group by s.customer, c.svc, c.revCode let totalQuant = sum(c.qty), totalDollar = sum(c.amt) ) a where rank() over (partition by revCode order by totalDollar desc) = 1 order by revCode, totalDollar; |
Once we have done this and have re-examined explain plan, we see that its length is cut in half, and that the execution process no longer includes listify functions. Running the query, then, should show much better performance, which in fact it does. Problem solved!
One final note: Our engineers are always looking for ways to improve our query optimizer. If in the course of optimizing one of your queries you do find in the explain text a rogue “listify” function (which is already rare, and getting rarer), please open a support ticket at support.couchbase.com, uploading your explain plan so they can have a look at it. In fact, directly as a result of their work with the customer mentioned above, this particular example (switch-case used with an aggregate function) will be, as of the 6.6 release of Couchbase, automatically rewritten by the optimizer.
Docs and Resources
The Couchbase docs site contains links to the N1QL for Analytics Language reference: https://docs.couchbase.com/server/current/analytics/introduction.html. You can also find a link there to a tutorial on the language and to the book by Don Chamberlin (co-inventor of the SQL language): https://www.couchbase.com/sql-plus-plus-for-sql-users.
Thanks very much to Dmitry Lychagin and Mike Carey for their careful review of this post.