
Our first Guest Post from the Community Writing Program comes from Nicolas Motte.

Nico is a full-stack engineer in the South of France. He released several native and hybrid mobile applications to iTunes and Google Play and started his own company in 2015. Today he is working at Amadeus as an Operations Manager and a trainer for Ops. He also invests in start-ups on his free time. He has experience in operational requirements and data stores (Memcached, Couchbase, MongoDB, Kafka, ZooKeeper, Elasticsearch).
Recently I have been working on a project to deploy a Couchbase cluster in OpenShift(1). Quickly I needed to simulate a workload, to assess the performance of the cluster and its tolerance to failure. At first I thought about migrating one of our applications to OpenShift, but that was way too painful for such a simple and common need. I also thought about creating my own injector, but I’m too lazy for that! Then I talked to Michael Hirschberg, a Couchbase champion, to understand how he validates new Couchbase releases or new hardware. He pointed me to cbc-pillowfight. In case you don’t know this tool, have a look here.
That looked very promising, all I had to do was to deploy it in OpenShift…but I had no idea how to do that! So ok, OpenShift runs the applications in Docker containers, it meant the first step was to create a Docker image. After a few tries, I came up with this Dockerfile based on CentOS, very simple and straightforward. The important bit was to use only one RUN command to reduce the number of layers and pass the cbc-pillowfight parameters as Docker parameters, to make it generic. The Dockerfile can be compiled and pushed to a repo with these commands:
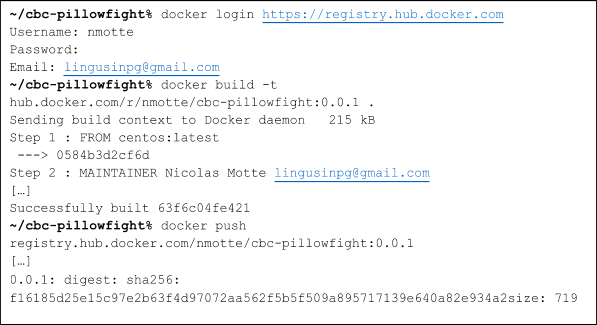
You can find the compiled Docker image here. Now, all I needed was to create an OpenShift template, taking all the previous parameters in input.I added a replication controller to scale easily my injection and a suffix is appended to its name so you can deploy several injectors with different parameters. And we’re done! Pretty simple, right? Now I can simulate any kind of traffic to my Couchbase cluster running in OpenShift and increase this traffic simply by adding replicas to my replication controller.
Here is an example how to use it:
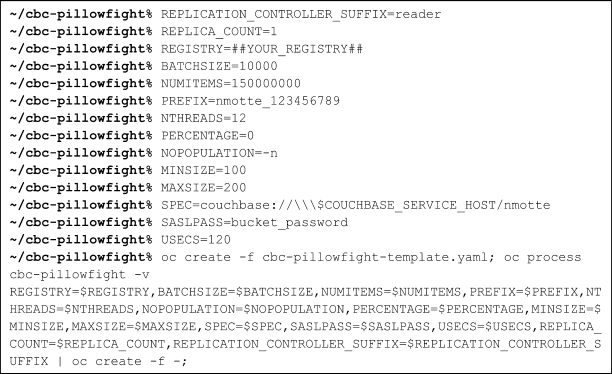
I easily reached 46k ops/sec in a tiny environment, and it is honestly super convenient to use. I uploaded a youtube video to show you concretely how to use it. Here are the details of my environment:
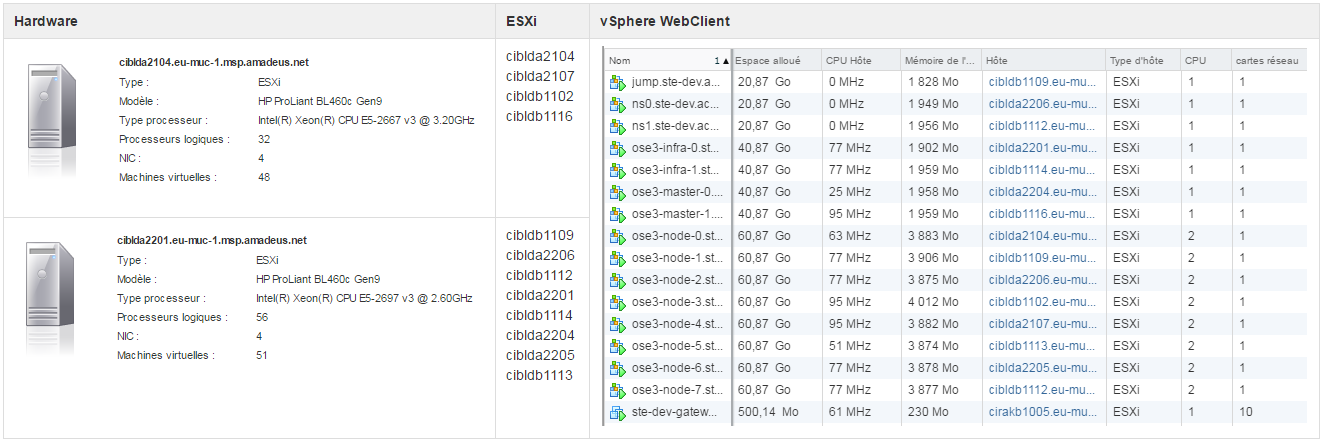
Hardware
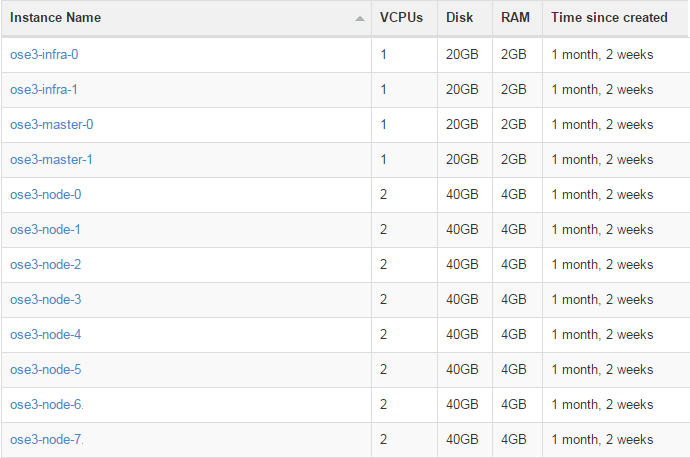
VMs
Storage

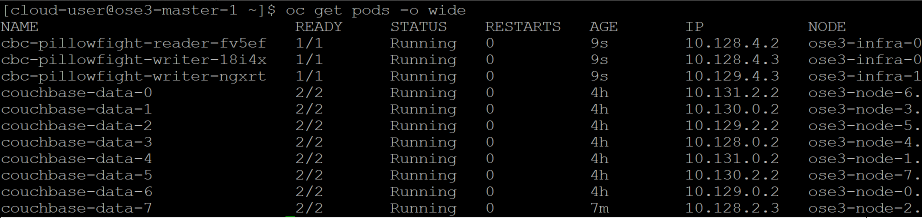
Distribution of Pods
Couchbase Console
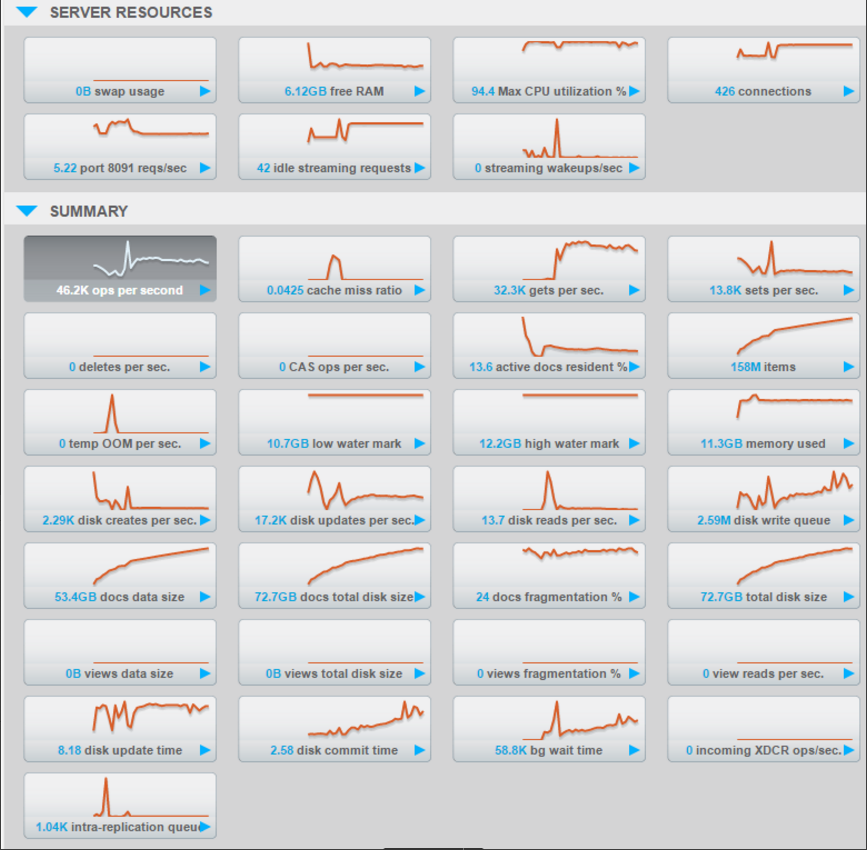
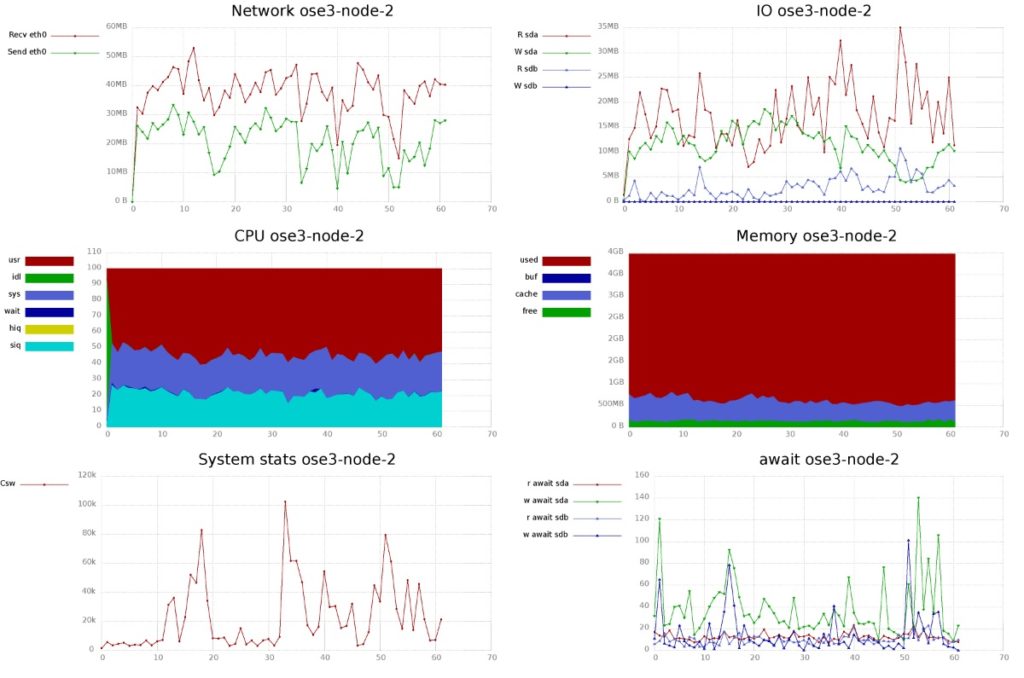
We can clearly see that the bottleneck of my environment is the CPU. I could improve the performance by adding more vCPUs to my VMs, but that’s not the point of this post.
I strongly believe the integration of datastores in OpenShift will become more and more popular in local environments at least, most probably in test environments too and maybe even in production, once it will be supported by the different vendors. It is a great way to standardize the management of the data layer. This OpenShift template for cbc-pillowfight will then be the perfect tool to generate a workload on your beloved Couchbase cluster!
-
Deploying Couchbase in OpenShift is not yet supported