
Creating the right search index and tuning its various configurations is very essential to the smooth working of any Full-Text Search production systems. These operational aspects play a key role in improving the indexing and querying performance of the search systems. We encourage every user of Search service to get familiar with the below concepts of index management and use it judiciously in their cluster. So you may scroll further to explore a few effective operational tips on Search service like memory quota, index partitions, replicas, aliases, and failover-recovery rebalance.
1. Provision Sufficient Memory Quota
The default memory quota for Search service is 512MB and this won’t be sufficient enough to support any production scale search systems. So it’s recommended to revise the Search RAM quota to more meaningful values as a part of the sizing of the cluster.
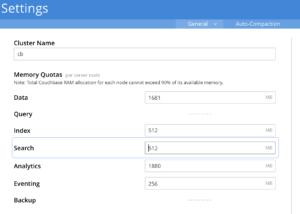
The Search service doesn’t mandate any minimum memory-resident ratio for its index. Nevertheless, the users are advised to spare enough Search memory quota for a healthy resident ratio of the index. This lets the system have sufficient memory available to perform the indexing, querying, or other lifecycle operations like rebalances, etc.
Below are a few symptoms for insufficient memory quota in a search cluster,
- Queries getting rejected due to HTTP 429 error code from the server.
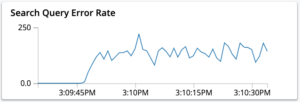
This rate-limiting is applied for respecting the configured memory quota for the search service. It rejects an incoming query when there isn’t enough memory available for serving the query without exceeding the set memory quota. You might notice an increase in the query error rate on the index monitoring page.
- A mounting number of slow queries in the system.
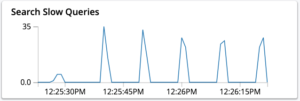
Spikes in slow queries could also happen due to the scarcity of operational memory in the system.
- Increase in the average latency of the queries.
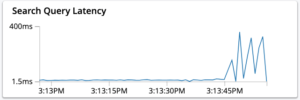
A gradual increase in query latency could also happen due to a lack of operational memory in the system.
All the above query statistics can be monitored over the built-in index stats page in the Couchbase server.
2. Spare Enough Memory for filesystem cache.
Another main aspect while configuring the Search memory quota is to leave enough leeway RAM for the Operating System to manage the file system cache. Under the hood, Search’s internal text indexing library (bleve) uses memory mapping for the index files. So having enough RAM spared for the operating system helps in keeping the hot regions of index files in the file system cache memory. This helps in better search performance.
The usual guideline is to set the Search memory quota to 60-70% of the available RAM in a Search node.
Configuring enough RAM memory in the system and allocating sufficient Search quota memory is essential for optimal search performance.
Symptoms – Search service getting OOM killed by the OS on a recurring basis during the indexing or querying process could hint at a lack of RAM memory in the system too.
3. Avoid Service Multi-Tenancy with Search Nodes
Hosting multiple services on a single node has the risk of potential resource contention among the services. Even setting a resource quota for every service won’t help to completely avoid this.
For example, Search service heavily depends on the available RAM memory beyond the configured memory quota for better memory mapping performance. But other services running on the same node could eat up these available RAM to affect the search performance inadvertently. The same goes for CPU cores as well.
Debugging and nailing down performance problems or the initial sizing of the Search system becomes much easier with single service hosted nodes.
Hence users are encouraged to at least start with single service search nodes during the initial deployment period.
4. Index Topology Considerations
-
Number of Index Partitions
Depending on the amount of data indexed, adjust the number of index partitions and its distribution across nodes/CPU cores to optimize the service performance.
Too many partitions increase the scatter-gather cost, and too few partitions would limit the search parallelization.
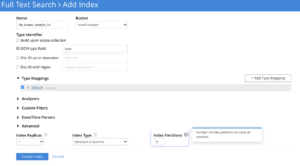
There is no generic predefined index partition count that fits all use cases. Users have to explore this empirically for each of their use case SLAs.
If the user is only having a few millions of data, overriding the default partition count of 6 to smaller values like 1 or 2 is recommended.
Few important points to keep in mind with the number of index partitions are,
- Helps in better allocation of indexing and query workloads across available nodes depending on the cluster size.
- Relatively smaller partitions on multiple nodes help in faster rebalance operations.
- Partitions help in better CPU core utilization.
- Depending on the amount of data getting indexed, it’s advisable to adjust the partition count so that the partitions aren’t very huge.
-
Number of Replicas
Replica serves only the purpose of high availability in Search Service today. So whenever a node goes down for any reason, users can perform a failover rebalance of the faulty node. This would immediately serve the live traffic from the replica partitions and service remains live to the end-users seamlessly.
Replica numbers need to be explicitly configured by the user during the index creation time.
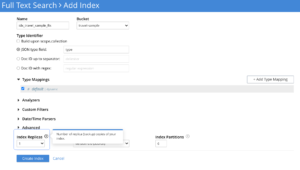
By default, search services do not enable partition replicas during the index creation.
Users are encouraged to configure a replica count of either 1 or more depending on the high availability requirements.
-
Failover And Recovery
If the user needs to temporarily take out a node from the cluster for any hardware or software maintenance operations, then they could try failing over the node. During the Failover of a search node, all the index partition data residing in the node is preserved.
Once the maintenance operations are over, then can try the “Recover” option to add it back to the cluster. As you are recovering the same node here, the search service will be able to reuse all the existing index partition data residing in the recovered node. And this would result in a really faster node recovery operation.

With replica partitions, the search service should be able to failover and recover nodes for maintenance without any service downtime.
5. Stricter Merge Policy for Update Heavy Use cases
A search index usually comprises a number of index files called segments. These segments are created by the document mutations(insert/update/delete) occurring in the data source/bucket. While serving a search request, FTS has to search through all these segments sequentially. Hence higher the number of segments, the slower the index search operations.
At the index storage layer, a background merger process keeps merging these smaller disk segment files into a stable set of larger segments. This merger behavior is controlled by the merge policy which can be specified over the index definition. An overly aggressive merger could steal more resources(disk and CPU) from other competing threads of the life cycle or query operations in an index. Hence we have kept the default merge policy to be generic enough to work with various use cases.
At any given moment, the default merge policy would try to result in a bunch of index segments that follow a logarithmic staircase pattern of growing segment sizes as below.

But there could be situations where overriding the merge policy is worth checking further and let’s explore them.
-
Faster reclaiming of the disk space with update/delete rich workload.
FTS has “append-only” storage which would mark the document entries in existing segments as deleted/obsolete by the flip of a bit upon any update/delete operations. The actual release of disk space will occur only when these segments get merged/compacted during the concurrent merge cycle. FTS’s default merge-policy will favor the merging of smaller segments over bigger gigantic segments to optimize the disk IO and CPU. This could leave a long wait period for reclaiming the disk space of the updated/tombstoned documents which belonged to those bigger segments, as the bigger segments get selected for merge operations infrequently.
The amount of reclaimable disk space any instant is exposed to users over a stat called num_bytes_used_disk_by_root_reclaimable.
If the user consistently sees significant values for the above stat, then it indicates the need for a stricter compaction policy for the index. The merge config knobs also have the provision to favor the selection of segments which have more obsolete/deleted contents during the compaction/merge process.
-
Better search performance for read-heavy workloads.
We have already learned that every search request is served after consulting each of these segment files within an index. Hence the overhead of serving a search would be higher with a larger number of segments files.
A lesser number of segments helps to improve search performance. So it is recommended to reduce the number of segment files whenever feasible. (off-peak hours)
Compaction policy can be overridden using the index definition update rest endpoint. Please contact us for further details on how to override the default compaction policy for an index.
6. Make Use of Index Aliases
An index alias points to one or more Full-Text Indexes, or to additional aliases: its purpose is therefore somewhat comparable to that of a symbolic link in a filesystem. Queries on an index alias are performed on all ultimate targets, and merged results are provided.
The use of index aliases permits indirection in naming, whereby applications refer to an alias-name that never changes, leaving administrators free periodically to change the identity of the real index pointed to by the alias. This may be particularly useful when an index needs to be updated: to avoid down-time, while the current index remains in service, a clone of the current index can be created, modified, and tested. Then, when the clone is ready, the existing alias can be retargeted, so that the clone becomes the current index; and the (now) previous index can be removed.
Index alias creation details can be found here
7. Index Definition Update Gotchas
Users have an option to update the index definition whenever they need to change properties of the index related to type mappings, partitions, replicas, storage, or persistence.
One thing to keep in mind while updating an index definition is that few of the updates would result in the rebuild of the index from scratch.
Index Rebuilding Updates
Any type of mapping or partition count related updates always rebuilds the index. So these changes would affect the live traffic. But usually, these types of index definition updates happen towards the early deployment phase of the cluster.
Non-Rebuilding Updates
The remaining index property updates would be instantaneous. Updates would only result in a restart or refresh of the underlying components. The index should be up and running within a down period of only a few seconds. Hence users may try these during the non-peak traffic hours.
Index definition updates like changing the replica counts, storage engine properties belong to this category.
For any Search system-related queries, users may reach out to us here.
For any FTS query tips, users may check the below blog,
Great article, Sreekanth.