
Couchbase Server 5.0 and 5.5 were two big releases. Let’s see some of the new cool and old features which developers can’t miss out:
1) Sub Documents
This feature has been here for a while, but it’s still worth to mention. Some Key-Value stores only allow you to bring the whole document all-together, which is a reasonable characteristic. After all, it is a Key-Value Store. However, if you are using Couchbase as a KV, you can still manipulate parts of the document by specifying the path to it. Ex:
Given the following document:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
{ "name": "Douglas Reynholm", "email": "douglas@reynholmindustries.com", "addresses": { "billing": { "line1": "123 Any Street", "line2": "Anytown", "country": "United Kingdom" }, "delivery": { "line1": "123 Any Street", "line2": "Anytown", "country": "United Kingdom" } }, "purchases": { "complete": [ 339, 976, 442, 666 ], "abandoned": [ 157, 42, 999 ] } } |
You can manipulate parts of the document by simply specifying the path to it, like GET(‘addresses.billing’) or ARRAY_APPEND(‘purchases.abandoned’, 42)
If you want to read more, check out this blog post or our official documentation.
2)Eventing
Eventing is clearly one of the coolest features in Couchbase 5.5 and we already have a bunch of blog posts covering it, like here or here. For those who haven’t heard it yet, the Eventing Service enables you to write server-side functions that are automatically triggered whenever a document is inserted/updated/deleted. Those functions can be easily written using a JavaScript-like syntax:
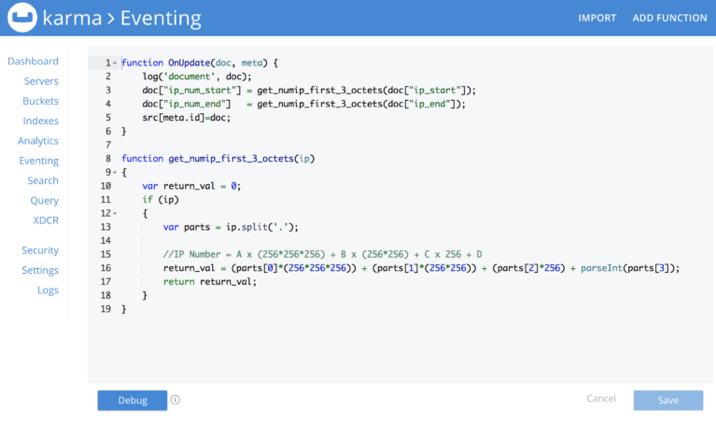
Additionally, you can also call endpoints in your application via curl:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
function OnUpdate(doc, meta) { if (doc.resourceType != 'Observation') return; let reference = doc.subject.reference; let url = "http://localhost:8080/events/" + reference.substr(9); let data = JSON.stringify({ "reference": doc.subject.reference, "code": doc.code.coding[0].code, "recordedAt": doc.issued, "value": doc.valueQuantity.value }); let curl = SELECT CURL($url, { "request": "POST", "header": [ "Content-Type: application/json", "accept: application/json" ], "data": $data }); curl.execQuery(); } function OnDelete(meta) {} |
3)ANSI Joins
Couchbase allows you to use joins in your queries for quite a long time, but so far, it could only be accomplished by using our own syntax. Since Couchbase 5.5 you can also use the ANSI JOIN syntax:
|
1 2 3 4 5 6 7 |
SELECT DISTINCT route.destinationairport FROM `travel-sample` airport JOIN `travel-sample` route ON airport.faa = route.sourceairport AND route.type = "route" WHERE airport.type = "airport" AND airport.city = "San Francisco" AND airport.country = "United States"; |
You can read more about it here.
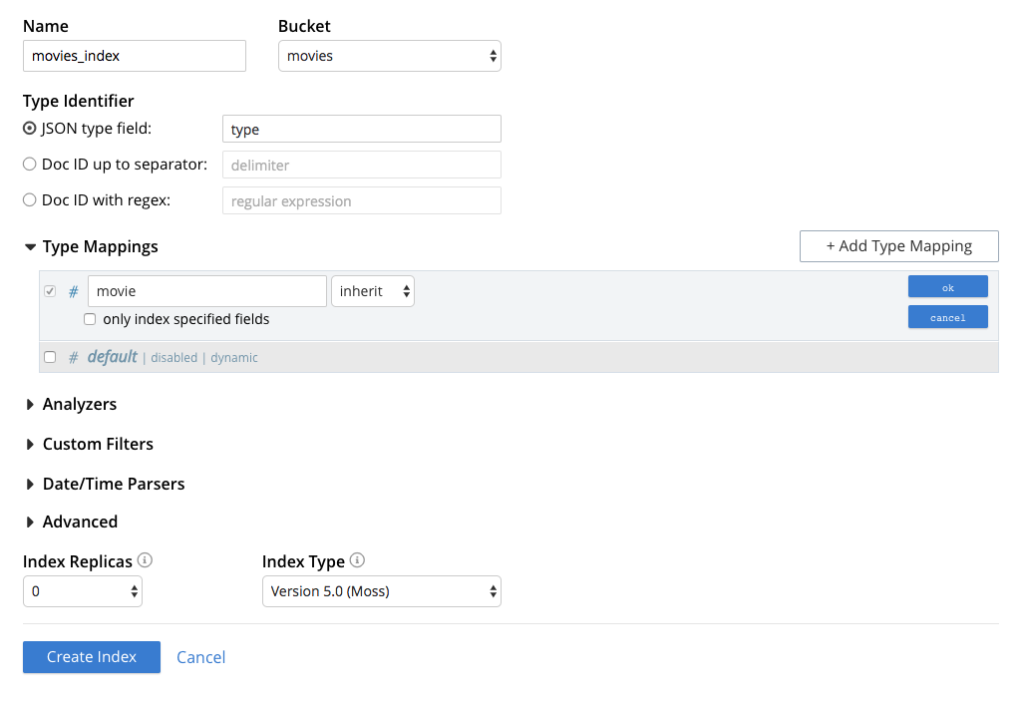
4)Full-Text Search
Most of the user-facing applications eventually need to implement some sort of advanced search. This kind of feature usually requires you to push data to a third-party tool like Solr or Elastic Search. However, adding such tools increases the cost and complexity of your infrastructure significantly, not to mention all the code necessary to push Object/Document changes to these tools.
Starting with Couchbase 5.0, you can simply create full-text search index in the web console and start making full-text searches directly from the database:
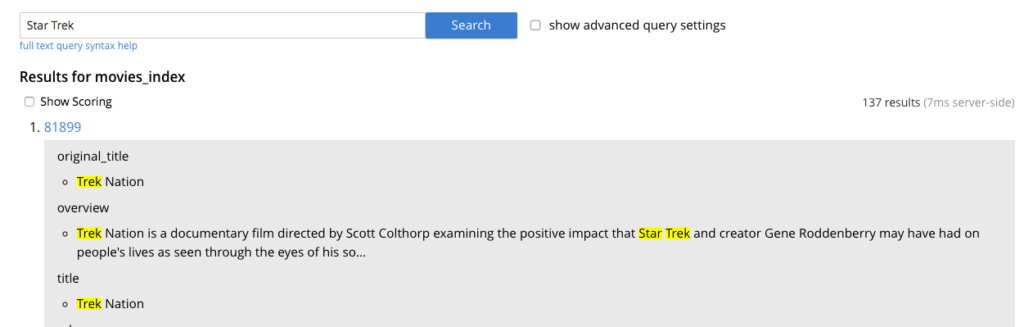
Highlighting search results:
Hot to make a simple search via SDK:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
@Override public List<SearchQueryRow> searchQuery(String word) { String indexName = "movies_index"; QueryStringQuery query = SearchQuery.queryString(word); SearchQueryResult result = movieRepository.getCouchbaseOperations().getCouchbaseBucket().query( new SearchQuery(indexName, query).highlight().limit(20)); List<SearchQueryRow> hits = new ArrayList<>(); if (result != null && result.errors().isEmpty()) { Iterator<SearchQueryRow> resultIterator = result.iterator(); while (resultIterator.hasNext()) { hits.add(resultIterator.next()); } } return hits; } |
You can view the official documentation here.
5) Faster queries, GROUP BYs and Aggregation Pushdown
Regardless of the database, aggregations (min, max, avg, etc) and GROUP BYs operations have always been problematic in terms of performance. In order to tackle this issue, with Couchbase 5.5, you can leverage your indexes to speed up these types of queries:
|
1 2 3 4 5 |
SELECT country, state, city, COUNT(1) AS total FROM `travel-sample` WHERE type = 'hotel' and country is not null GROUP BY country, state, city ORDER BY COUNT(1) DESC; |
~90ms – Query plan of the query above

~7ms – Same query as before but using a proper index

You can read the full article here.
6)Role-Based Access Control and X509 cert
Databases are the jackpot for any malicious intruder, which is why it is never too much to add an extra layer of security. With Couchbase, you can authenticate clients using X.509 certificates and limit their access via Role Based Access Control (RBAC):
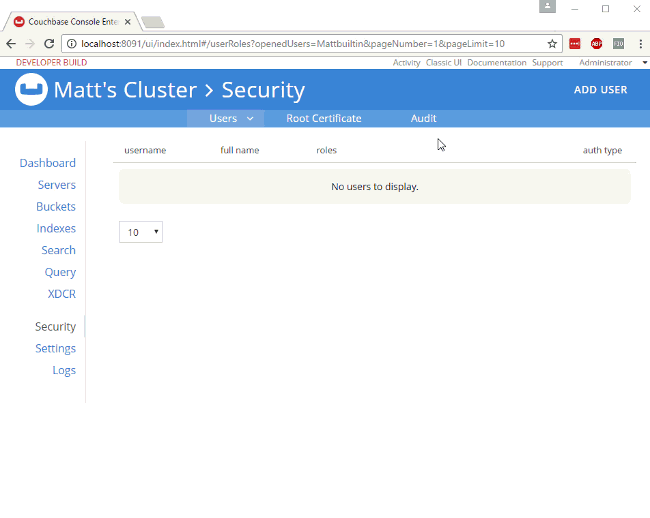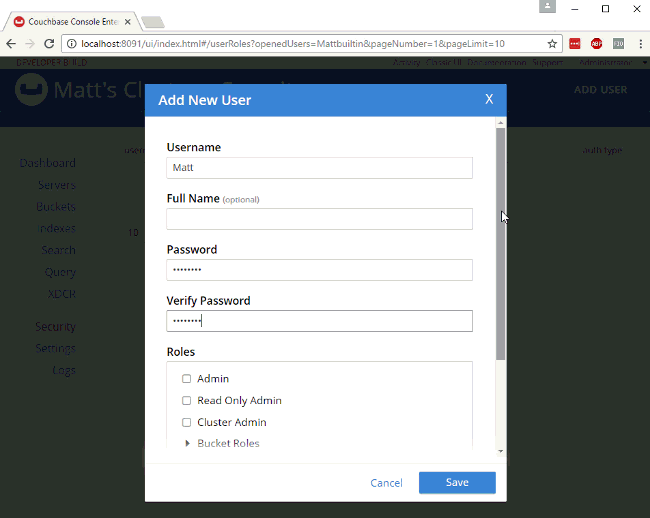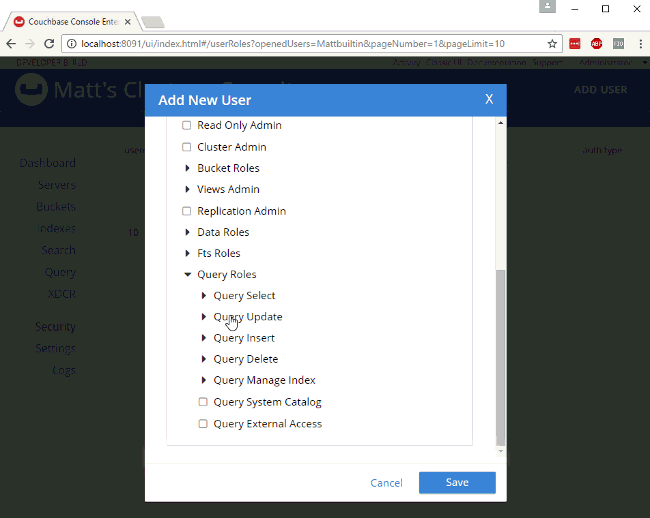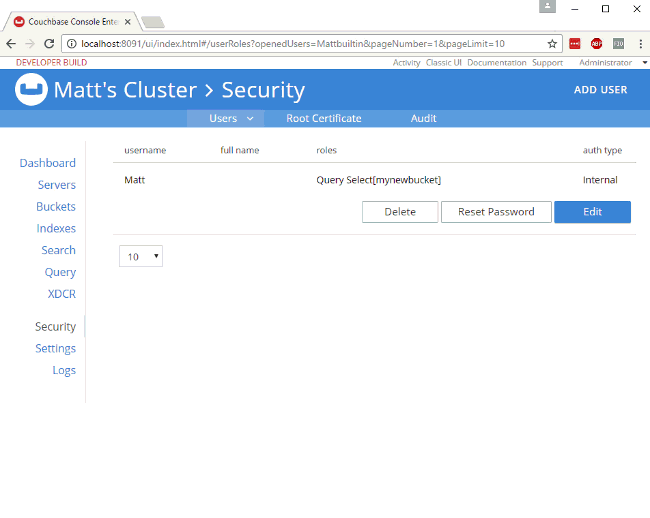
You can also grant permissions via N1QL. Let’s see how granting a SELECT permission for the user denis in the bucket some_bucket would look like:
|
1 |
GRANT ROLE query_select(some_bucket) TO denis; |
You can read more about it here or here.
7)Field Encryption
Encryption at rest is one of the most basic forms of security, and you can easily encrypt/decrypt fields using the Couchbase’s Java Encryption:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
public static class Person { @Id public String id; @EncryptedField(provider = "AES") public String password; //The rest will be transported and stored unencrypted public String firstName; public String lastName; public String userName; public int age; } |
Read more about it here or here.
8) Reactive SDK
We also offer a reactive SDK, which is not something easy to find in a good portion of the database providers. This is mostly due to the fact that our SDK itself is implemented reactively.
Reactive programming is really important for performance and resource optimization. If you are not familiar with this concept yet, I highly recommend this article, which gives you a quick overview of why you might consider using reactive programming in your persistence layer.
We have an extensive material on this topic. If you would like to know more, you can start here or here.
9) “Fine Speed Tuning” via SDK
At Couchbase, we try to empower developers to fine-tune their performance even at the document level, so developers can decide, case-by-case, what is the best trade-off for each scenario.
Let’s take a look, for instance, at how Couchbase stores data. By default, as soon as the server acknowledges that a new document should be stored, it already sends the response back to the client saying that your “request has been received successfully” and asynchronously, we store and replicated the document.
This approach is very good for speed but there is a small chance of losing data if the server crashes when the document is still in the server’s memory. If you want to avoid that, you can specify via SDK that you would like to receive the confirmation only after the document has been replicated or stored in the disk:
|
1 2 3 4 5 |
movieRepository.getCouchbaseOperations().save(movie, PersistTo.ONE, ReplicateTo.NONE); //or movieRepository.getCouchbaseOperations().save(movie, PersistTo.ONE, ReplicateTo.TWO); ... movieRepository.getCouchbaseOperations().save(movie, PersistTo.NONE, ReplicateTo.ONE); |
Why allow such a thing? Well, because if you can afford the small chance of losing this data if the server crashes, you can improve your performance significantly. This is not an all-or-nothing decision as you can decide which parts of the system worth such a risk.
You can also do something similar with your queries. In this case, if you would like to wait for the indexes/views to be updated based on the last changes or whether you are fine with the small chance of not returning the most recent version of your documents:
|
1 2 3 4 |
//You can use ScanConsistency.REQUEST_PLUS, ScanConsistency.NOT_BOUNDED or ScanConsistency.STATEMENT_PLUS N1qlParams params = N1qlParams.build().consistency(ScanConsistency.REQUEST_PLUS).adhoc(true); ParameterizedN1qlQuery query = N1qlQuery.parameterized(queryString, JsonObject.create(), params); resourceRepository.getCouchbaseOperations().getCouchbaseBucket().query(query); |
There are a few other features in our SDK that can also be optimized, and all these small decisions can significantly improve your performance at scale.
10) Response Time Observability
I have already mentioned this item in my previous blog post, but I think it worth being mentioned again. Since version 5.5, we have introduced a new capability called Response Time Observability, which will provide to system developers a very simple way to observe response times relative to a (tune-able) threshold.
This feature, which uses OpenTracing format, logs slow requests followed by a bunch of details about it after each time interval, so you can easily identify the operations with poor performance.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 |
Apr 04, 2018 9:42:57 AM com.couchbase.client.core.tracing.ThresholdLogReporter logOverThreshold WARNING: Operations over threshold: [ { "top" : [ { "server_us" : 8, "local_id" : "41837B87B9B1C5D1/000000004746B9AA", "local_address" : "127.0.0.1:55011", "operation_id" : "get:0x6", "dispatch_us" : 315, "remote_address" : "127.0.0.1:11210", "total_us" : 576 }, { "server_us" : 8, "local_id" : "41837B87B9B1C5D1/000000004746B9AA", "local_address" : "127.0.0.1:55011", "operation_id" : "get:0x5", "dispatch_us" : 319, "remote_address" : "127.0.0.1:11210", "total_us" : 599 }, { "server_us" : 8, "local_id" : "41837B87B9B1C5D1/000000004746B9AA", "local_address" : "127.0.0.1:55011", "operation_id" : "get:0x4", "dispatch_us" : 332, "remote_address" : "127.0.0.1:11210", "total_us" : 632 }, { "server_us" : 11, "local_id" : "41837B87B9B1C5D1/000000004746B9AA", "local_address" : "127.0.0.1:55011", "operation_id" : "get:0x3", "dispatch_us" : 392, "remote_address" : "127.0.0.1:11210", "total_us" : 762 }, { "server_us" : 23, "local_id" : "41837B87B9B1C5D1/000000004746B9AA", "local_address" : "127.0.0.1:55011", "operation_id" : "get:0x1", "decode_us" : 9579, "dispatch_us" : 947, "remote_address" : "127.0.0.1:11210", "total_us" : 16533 }, { "server_us" : 56, "encode_us" : 12296, "local_id" : "41837B87B9B1C5D1/000000004746B9AA", "local_address" : "127.0.0.1:55011", "operation_id" : "upsert:0x2", "dispatch_us" : 1280, "remote_address" : "127.0.0.1:11210", "total_us" : 20935 } ], "service" : "kv", "count" : 6 } ] |
Response Time Observability is on by default, and we have already defined a set of thresholds to avoid logging healthy requests. If you want to push the limits of your cluster, you can even set smaller thresholds manually. You can read more about it here.