- Solutions
-
-
Adaptive Applications

Get AI-ready with hyper-personalized apps!
Next level customer experiences require adaptive applications
Learn more
-
-
- Developers
-
-
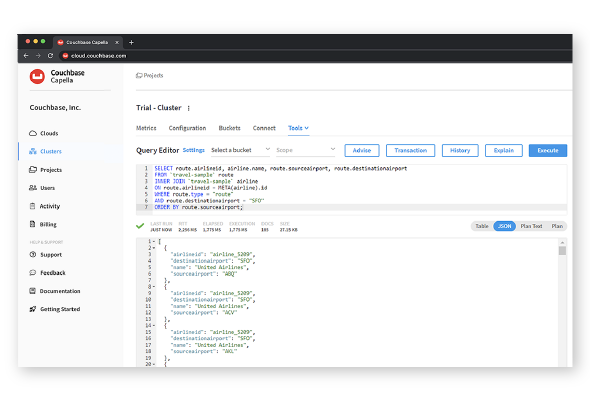
Capella Playground
-
-
- Resources
-
-
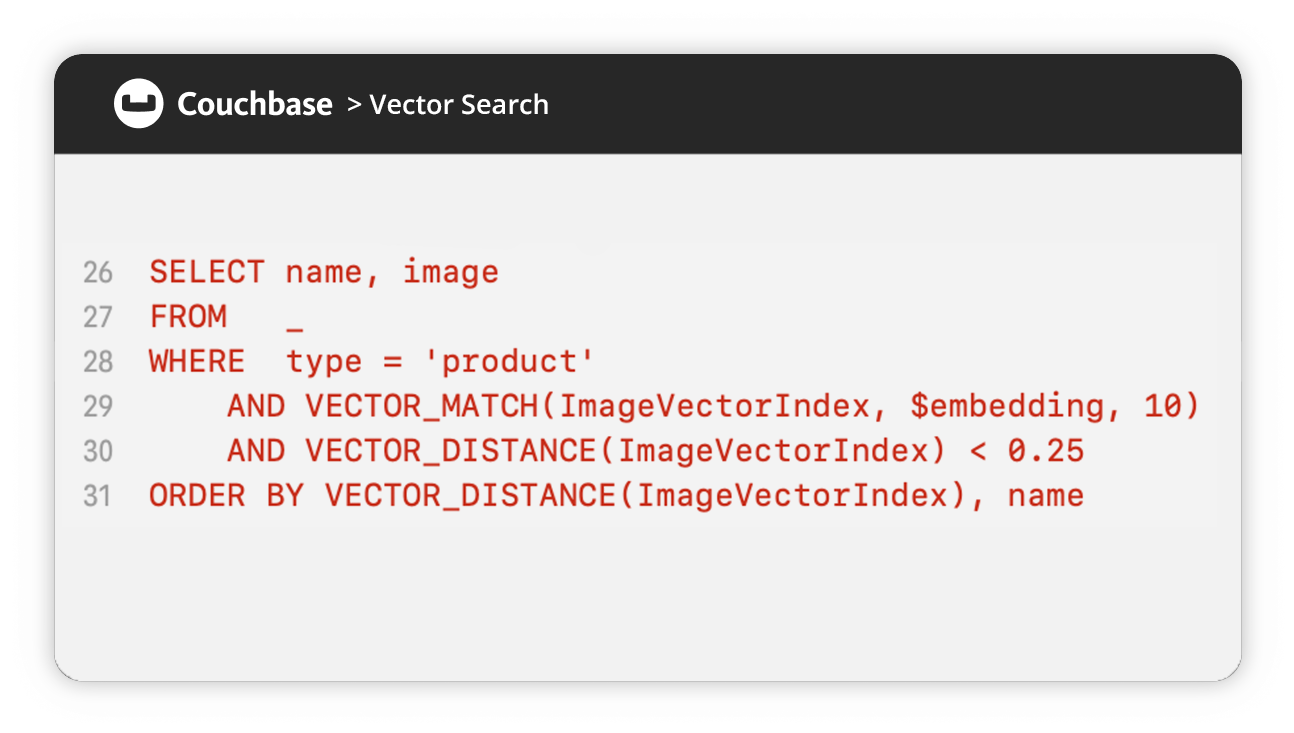
Vector Search
What's Vector Search and why is it important?
Get a quick overview of vectors, vector search, use cases, and key features.
Watch
-
-
Dealing with Memcached Challenges
Are you dealing with memcached problems like cold cache, heavy contention of RDBMS resources and lack of scale-out flexibility? Couchbase Server, a NoSQL database, can be used as an alternative drop-in replacement for your memcached tier to address these challenges.
Read WhitePaperDifference between memcache vs. memcached
The short answer is: nothing. The longer answer is that, because memcache is executed in the background on Linux systems (and is thus considered a “daemon”), the program file used to start the software is named memcached to follow daemon naming conventions. So, technically, memcache refers to the software and memcached refers to the name of the program file. But most people simply use memcached to refer to both at this point.
How do you pronounce memcached?
Is it memcached (as in ‘I just cached it’) or is it memcache-dee? Both are used widely in technical circles, but if you hold to its UNIX roots, you would pronounce it “memcache-dee.”
Memcached Challenges
Challenge 1: Cold Cache
Symptoms
Slowdown or collapse of the data service layer due to heavily overloaded RDBMS when memcached nodes go down (on failure or for maintenance)
Solution
Data is automatically replicated across the Couchbase cluster, providing high availability of data even on failures
Challenge 2: Heavy RDMBS Contention
Symptoms
Multiple requests for data items that do not exist in the cache results in sudden shifting of load to the relational database causing heavy contention
Solution
By replicating data across the cluster, Couchbase Server provides consistent performance without shifting load to the RDBMS layer
Challenge 3: Lack of Scalability
Symptoms
Adding or removing memcached nodes is complicated and causes unpredictable application performance degradation
Solution
Auto-sharding and online rebalancing in Couchbase Server provides easy non-disruptive expansion of the cluster
Challenge 4: Complex Monitoring
Symptoms
Management of individual memcached nodes increases the complexity of operations and lacks a single consistent view of the caching layer
Solution
Couchbase Server provides an in-built admin console for cluster wide management and monitoring as well as RESTful APIs for easy automation and third-party integration
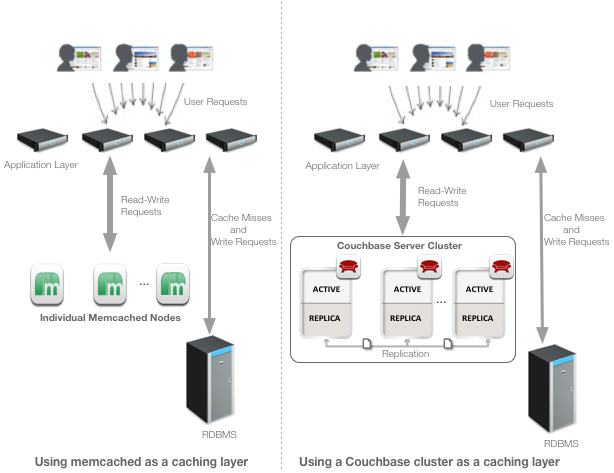
Reference Architecture
The architecture diagram below depicts a memcached environment before and after the caching tier is replaced by Couchbase Server.
One of the use cases of Couchbase Server is to function as a caching layer within a typical web-based architecture, as shown above. The low latency, consistent performance and linear scalability of Couchbase Server make it suitable as a memcache tier replacement; its built-in caching technology enables sub-millisecond response times that match those of memcached.
Data in Couchbase Server is automatically partitioned and distributed across cluster nodes. Each node in the Couchbase cluster is identical and data is replicated across the nodes so that each node stores both active and replica documents. Couchbase clients are topology-aware and automatically route requests directly to the appropriate node.
Additionally, the admin console in Couchbase Server enables you to monitor and manage at the cluster level (not the server level, as with memcached), simplifying your system management and operations, and saving you time.