
Couchbase Blog
Featured Posts



Are you ready for the longest running and largest Java Ecosystem Conference in the world? We are so excited to see you at DevNexus 2024! Hosted in Atlanta, April 9-11, you will find 3 days, 6 full-day workshops, 14 tracks,...

User-defined functions (UDFs) are a very useful feature supported in SQL++. Couchbase 7.6 introduces improvements that allow for more debuggability and visibility into UDF execution. This blog will explore two new features in Couchbase 7.6 in the world of UDFs. Profiling...

Starting a new job is always a little bit nerve wracking. Will I fit in? Will my coworkers like me? What is the culture like? I don’t think this feeling ever goes away no matter if you are new in...
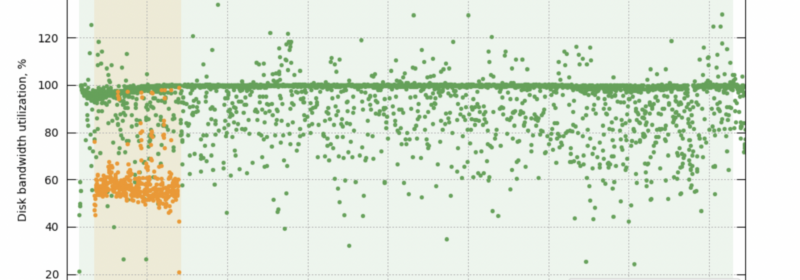
Faster scaling of database resources is essential for maintaining efficient and performant databases, especially with the increased pressure of data ingestion, growing query demands, and the need to handle failovers seamlessly. As application-driven query traffic is primarily handled by index...

When’s the last time you used a database? Most of us are so accustomed to user-friendly interfaces like TikTok, bank apps, and work programs that we don’t realize we’re interacting with databases all the time. We’re even less inclined to...

AWS Summit season is upon us and we are excited to share that we will be traveling to 15 cities across the globe! Our strategic collaboration with AWS is helping customers achieve cloud, analytics, AI, and other business goals they...
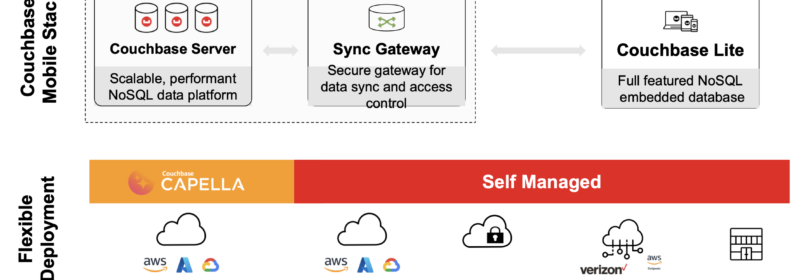
We’re pleased to announce the public beta release of Couchbase Lite 3.2 with support for vector search. This launch follows the coattails of vector search support on Capella and Couchbase Server 7.6. Now, with the beta launch of vector search...
If you’d like to watch this blog live, here is a video of Nyah Macklin & Jessica Rose walking through the process of installing Git and setting up a GitHub account. Watch below or read on. In our last post,...

Overview of Serverless Computing and Cloud Computing This blog post will discuss the main differences between serverless and cloud computing, their advantages and disadvantages, and their primary use cases. Keep reading to learn which type of computing is the best...

We are thrilled to announce the launch of Couchbase 7.6, a groundbreaking update poised to redefine the landscape of database technology. This latest release is a testament to our commitment to enhancing database technology, with a significant leap in AI...

Couchbase Capella™, our Database-as-a-Service offering, provides customers with a fully managed experience with performance, scalability, security, and manageability built in. Now, with webhook alert integration, customers can easily get Capella alerts in their third-party tools and use existing workflows to...

In the ever-evolving landscape of cloud computing and database management, seamless integration between data management platforms and cloud services is paramount for businesses looking to leverage the full potential of their data. Google Cloud’s Couchbase connector, a pivotal component of...
