

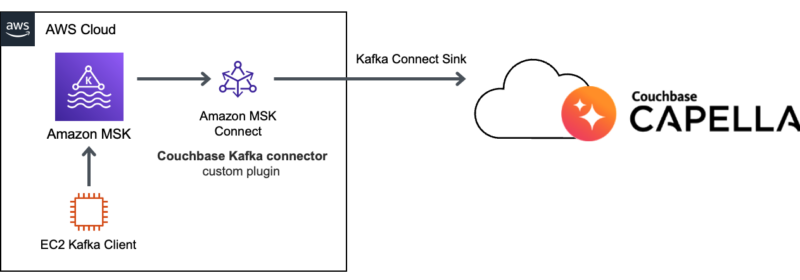
Streaming Data with Amazon MSK and Couchbase Capella
We see that a significant number of customers take advantage of Couchbase integration with Apache Kafka, by using Couchbase Kafka connector plugin that provides you capability to reliably stream data to and from Apache Kafka at scale. Apache Kafka is...
Saurabh Shabhag, Partner Solutions Architect, AWS April 17, 2024

Getting Ready for SAML: Essential Preparations for Couchbase Server Integration
In the evolving landscape of digital security, the integration of Couchbase with a Security Assertion Markup Language (SAML) Identity Provider (IdP) stands as a cornerstone for robust authentication mechanisms. Why Should You Implement SSO with Couchbase Server? Single Sign-On (SSO)...
Istvan Orban April 17, 2024

Join Us at DevNexus 2024 – Atlanta
Are you ready for the longest running and largest Java Ecosystem Conference in the world? We are so excited to see you at DevNexus 2024! Hosted in Atlanta, April 9-11, you will find 3 days, 6 full-day workshops, 14 tracks,...
Nyah Macklin - Developer Evangelist April 10, 2024

Embracing AI From Cloud to Edge With Google Distributed Cloud and Couchbase
Unveiled this week at Google Cloud Next, our longtime trusted partner Google announced the Google Cloud Ready Distributed Cloud program. The new program is designed to validate partner solutions on Google Distributed Cloud (GDC), Google’s AI-ready modern infrastructure that customers...
Mark Gamble, Dir Product & Solutions Mktg, Couchbase April 9, 2024

Couchbase Server 7.6 Awesomeness Unleashed: The Top 10 Features Every SRE Must Know!
Hey SRE Champions! Couchbase has just dropped a game-changing update, and we’re here to immerse you in real-world stories that highlight the top 10 features turning System Administrators, DevOps and Site Reliability Engineers (SREs) into superheroes. Join us for a...
Chris Malarky April 8, 2024

Improved Debuggability for SQL++ User-Defined Functions
User-defined functions (UDFs) are a very useful feature supported in SQL++. Couchbase 7.6 introduces improvements that allow for more debuggability and visibility into UDF execution. This blog will explore two new features in Couchbase 7.6 in the world of UDFs. Profiling...
Dhanya Gowrish, Software Engineer April 5, 2024

5 Cool Things I Learned in My First Month at Couchbase
Starting a new job is always a little bit nerve wracking. Will I fit in? Will my coworkers like me? What is the culture like? I don’t think this feeling ever goes away no matter if you are new in...
Caroline Kerns April 4, 2024
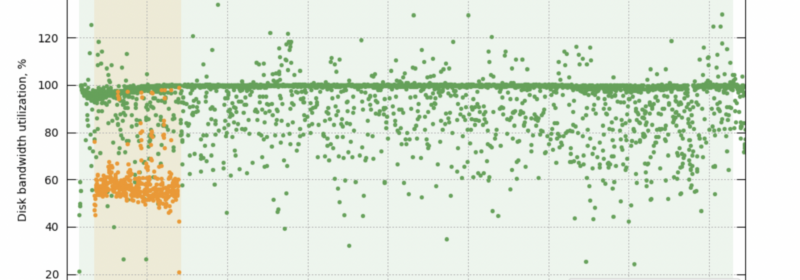
Rebalance Reimagined: Faster Scaling of Couchbase’s Index Service With File Transfers
Faster scaling of database resources is essential for maintaining efficient and performant databases, especially with the increased pressure of data ingestion, growing query demands, and the need to handle failovers seamlessly. As application-driven query traffic is primarily handled by index...
Varun Velamuri, Principal Engineer April 2, 2024

Column-Store vs. Row-Store: What’s The Difference?
When’s the last time you used a database? Most of us are so accustomed to user-friendly interfaces like TikTok, bank apps, and work programs that we don’t realize we’re interacting with databases all the time. We’re even less inclined to...
Couchbase Product Marketing March 29, 2024

AWS Summits 2024 Edition
AWS Summit season is upon us and we are excited to share that we will be traveling to 15 cities across the globe! Our strategic collaboration with AWS is helping customers achieve cloud, analytics, AI, and other business goals they...
Vinita Srivalsan March 28, 2024
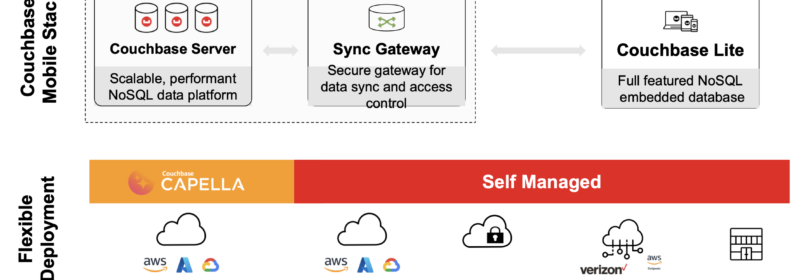
Vector Search at the Edge with Couchbase Mobile
We’re pleased to announce the public beta release of Couchbase Lite 3.2 with support for vector search. This launch follows the coattails of vector search support on Capella and Couchbase Server 7.6. Now, with the beta launch of vector search...
Priya Rajagopal, Senior Director, Product Management March 27, 2024
Learning on the Couch with FreeCodeCamp: Version Control – Git + GitHub
If you’d like to watch this blog live, here is a video of Nyah Macklin & Jessica Rose walking through the process of installing Git and setting up a GitHub account. Watch below or read on. In our last post,...
Nyah Macklin - Developer Evangelist March 26, 2024