
Aaron Benton is an experienced architect who specializes in creative solutions to develop innovative mobile applications. He has over 10 years experience in full stack development, including ColdFusion, SQL, NoSQL, JavaScript, HTML, and CSS. Aaron is currently an Applications Architect for Shop.com in Greensboro, North Carolina and is a Couchbase Community Champion.

FakeIt Series 1 of 5: Generating Fake Data
There are countless blog posts on data modeling, key and document patterns. All of these posts give a great introduction into how to structure and model your documents in Couchbase, but none of them tell you what to do next. In this blog series we are going to answer the question, what do you after you’ve defined your data model?
Users Model
For this series we will be working with a greenfield e-commerce application. As with most e-commerce applications, our application is going to have users so this is where we will begin.
We have defined a basic user model to start with.
|
1 2 3 4 5 6 7 8 9 10 11 |
{ "_id": "user_0", "doc_type": "user", "user_id": 0, "first_name": "Mac", "last_name": "Carter", "username": "Salma.Ratke", "password": "DvA6YrMGtgsKKnG", "email_address": "Ludie74@hotmail.com", "created_on": 1457172796088 } |
We’ve done the hardest part, which is defining our model, but now what?
- How do we represent this model?
- How do we document this model?
- Does this model rely on data from other models?
- How can data be generated from this model?
- How can we generate fake / test data?
Luckily for us there is a NodeJS project called FakeIt that can answer all of these questions for us. FakeIt is a command-line utility that generates fake data in json, yaml, yml, cson, or csv formats based on models which are defined in yaml. Data can be generated using any combination of FakerJS, ChanceJS, or Custom Functions. The generated data can be output in the following formats and destinations:
- json
- yaml
- cson
- csv
- Zip Archive of json, yaml, cson or csv files
- Couchbase Server
- Couchbase Sync Gateway Server
We can define a FakeIt model in YAML to represent our JSON model. This provides us a documented and data-typed model that we can communicate how our model should be structure and what the properties are for.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
name: Users type: object key: _id properties: _id: type: string description: The document id built by the prefixed "user_" and the users id doc_type: type: string description: The document type user_id: type: integer description: The users id first_name: type: string description: The users first name last_name: type: string description: The users last name username: type: string description: The users username password: type: string description: The users password email_address: type: string description: The users email address created_on: type: integer description: An epoch time of when the user was created |
You’re probably saying to yourself, “great, I’ve defined my model in YAML but what good does this do me?” One of the biggest issues developers face when beginning development is having data to work with. Often times an exorbitant amount of time is spent manually creating documents, writing throw away code to populate a bucket. Additionally you may have a full or partial data dump of your database that has to be imported.
These are time consuming, tedious and in the case of a data dump do not provide any insight or documentation into the available models. We can add a few simple properties to our FakeIt model describing how our model should be generated, and through a single file we can create an endless amount of fake randomized documents.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 |
name: Users type: object key: _id properties: _id: type: string description: The document id built by the prefix "user_" and the users id data: post_build: `user_${this.user_id}` doc_type: type: string description: The document type data: value: user user_id: type: integer description: An auto-incrementing number data: build: document_index first_name: type: string description: The users first name data: build: faker.name.firstName() last_name: type: string description: The users last name data: build: faker.name.lastName() username: type: string description: The username data: build: faker.internet.userName() password: type: string description: The users password data: build: faker.internet.password() email_address: type: string description: The users email address data: build: faker.internet.email() created_on: type: integer description: An epoch time of when the user was created data: build: new Date(faker.date.past()).getTime() |
We have added a data property to each of our models properties describing how that value should be generated. FakeIt supports 5 different ways to generate a value:
- pre_build: function to initialize the value
- build: function that builds a value
- fake: A FakerJS template string i.e. {{internet.userName}}
- value: A static value to use
- post_build: a function that runs after every property in the model has been set
These build functions are a JavaScript function body. Each of these functions is passed the following variables that can be used at the time of its execution:
- documents – An object containing a key for each model whose value is an array of each document that has been generated
- globals – An object containing any global variables that may have been set by any of the run or build functions
- inputs – An object containing a key for each input file used whose value is the deserialized version of the files data
- faker – A reference to FakerJS
- chance – A reference to ChanceJS
- document_index – This is a number that represents the currently generated document’s position in the run order
- require – This is the node require function, it allows you to require your own packages. For better performance require and seth them in the pre_run function.
For example, if we look at the username properties build function it would look like this:
|
1 2 3 |
function (documents, globals, inputs, faker, chance, document_index, require) { return faker.internet.userName(); } |
Now that we have defined how our model should be generated, we can start to generate some fake data with it.
With our users model saved to a file models/users.yaml, we can output data directly to the console using the command
|
1 |
fakeit console models/users.yaml |
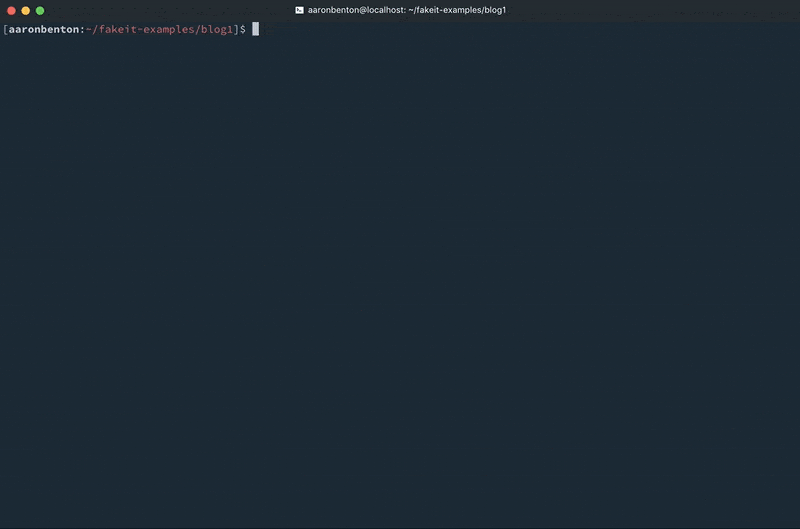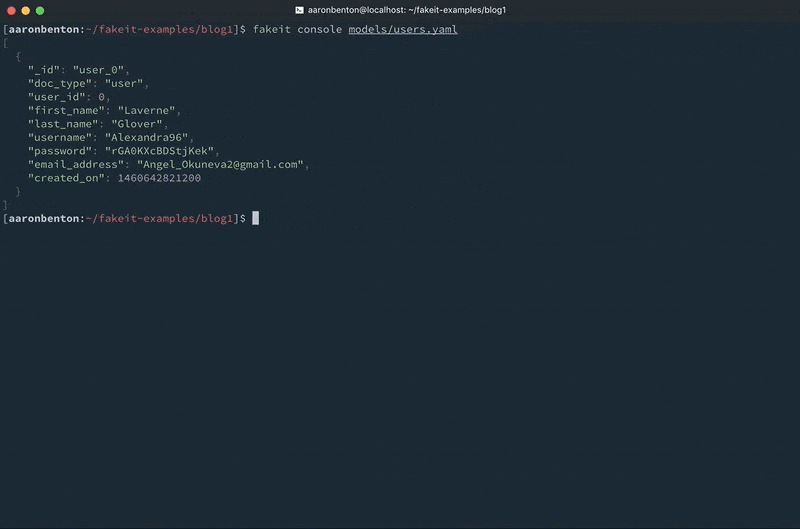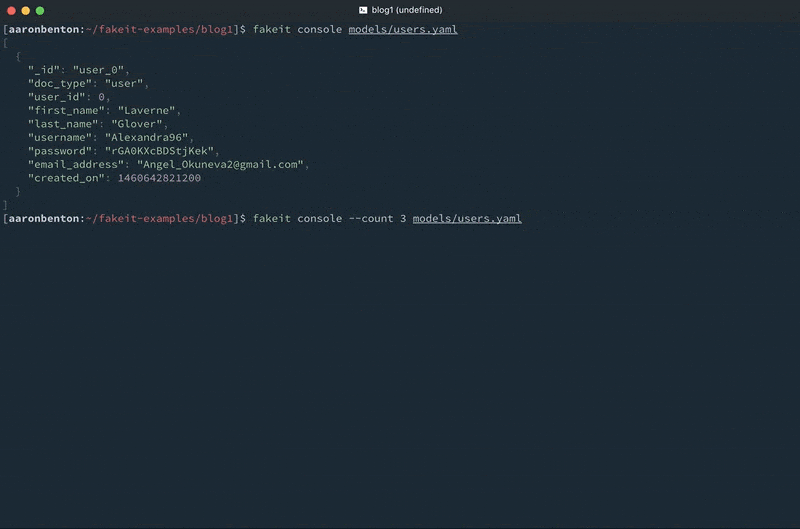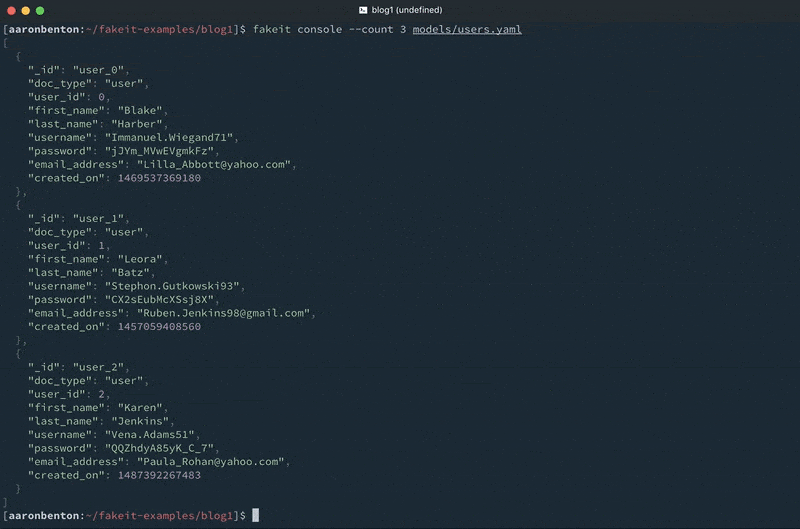
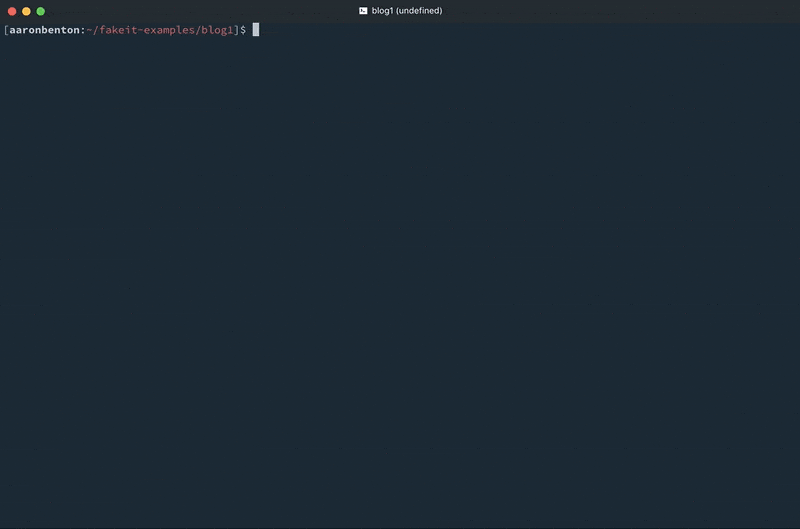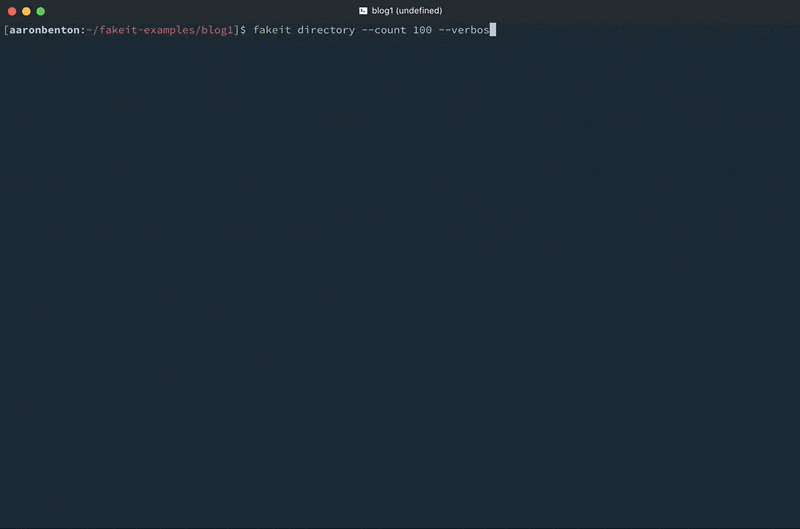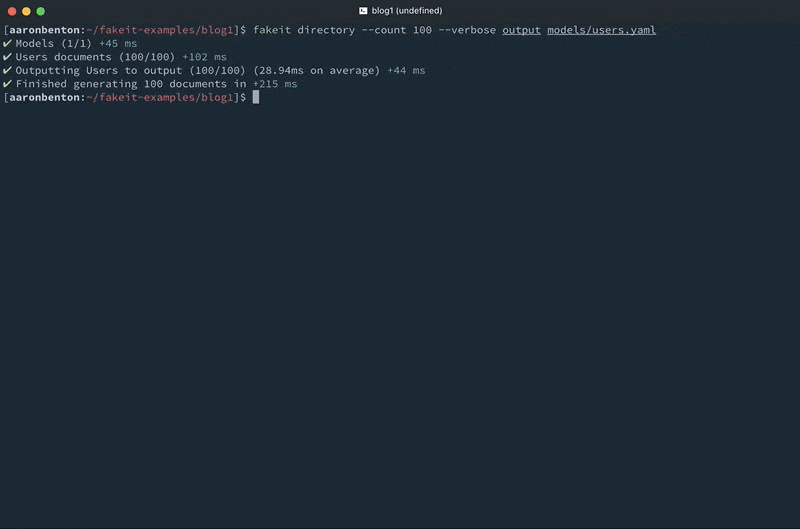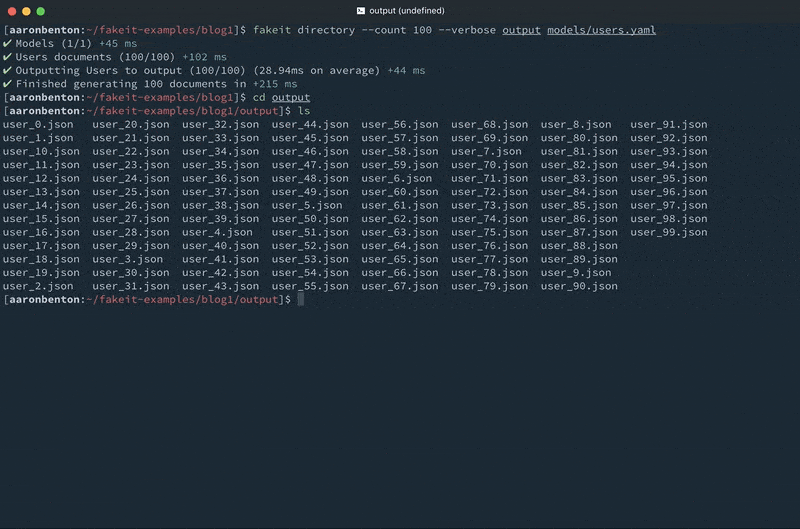
Using this same model we can generate 100 JSON files and save them into a directory named output/ using the command
|
1 |
fakeit directory –count 100 –verbose output models/users.yaml |
Additionally, we can create a zip archive of 1,000 JSON files using the command:
|
1 |
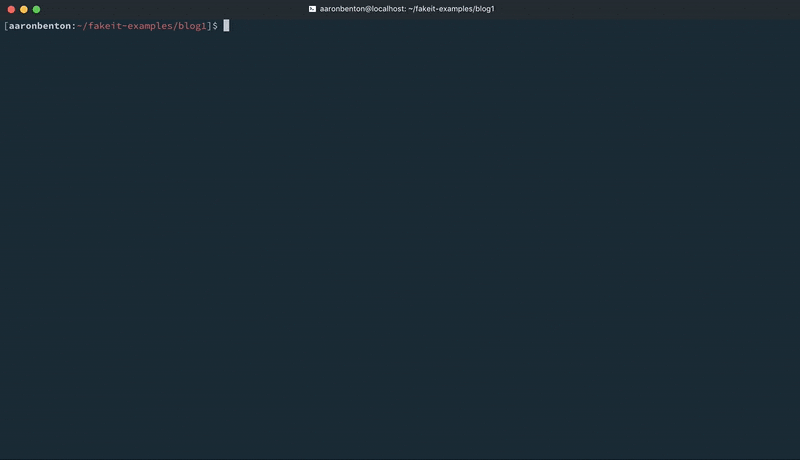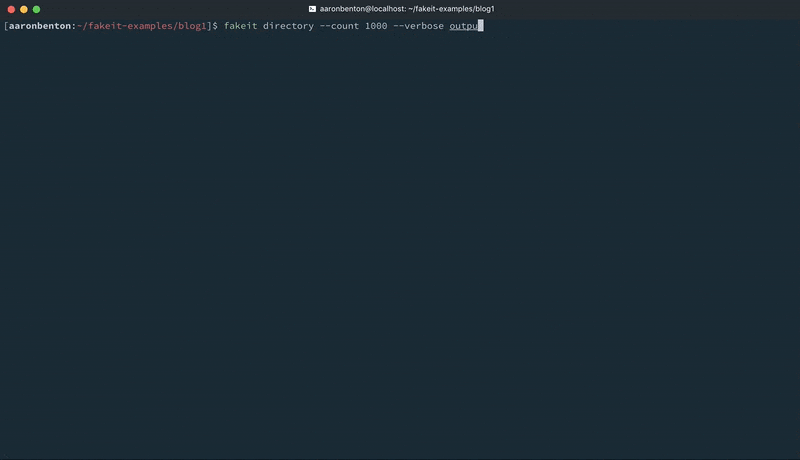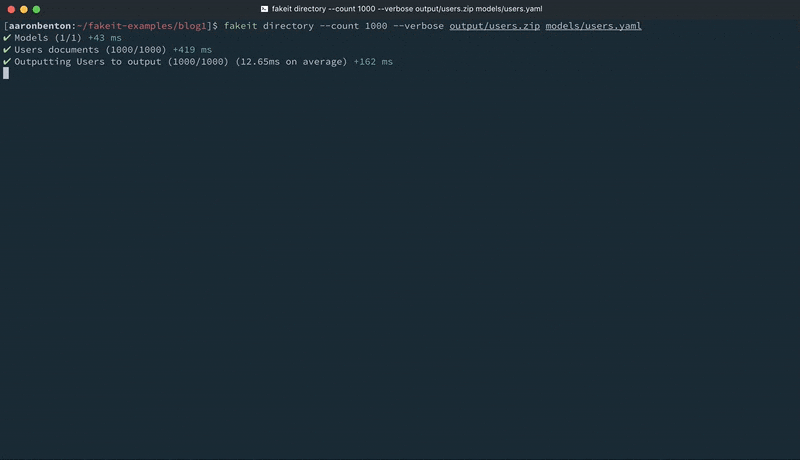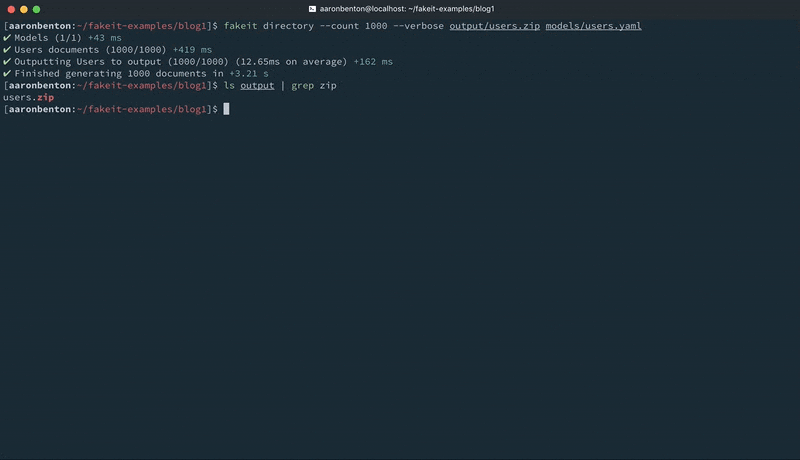
fakeit directory –count 1000 –verbose output/users.zip models/users.yaml |
We can even generate a single CSV file of our model using the following command:
|
1 |
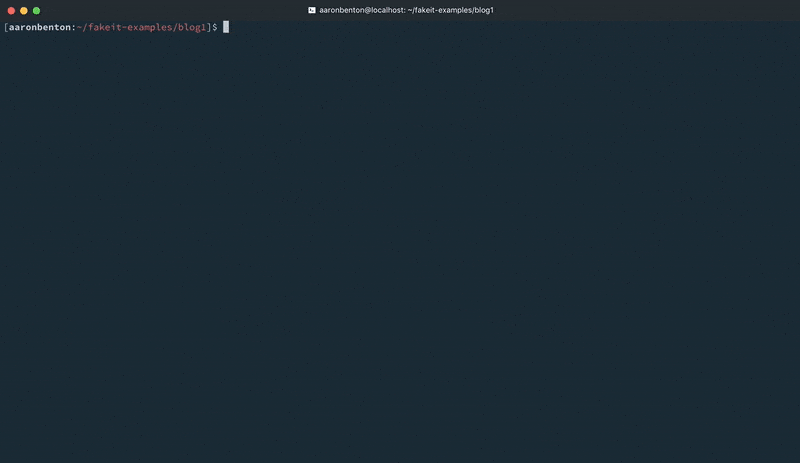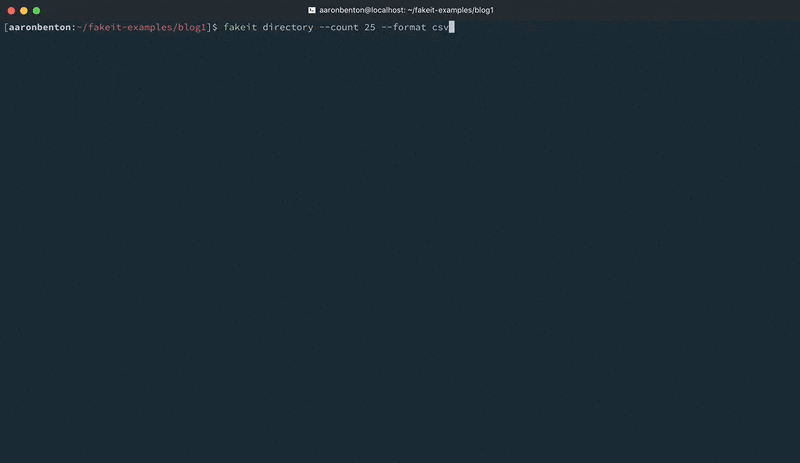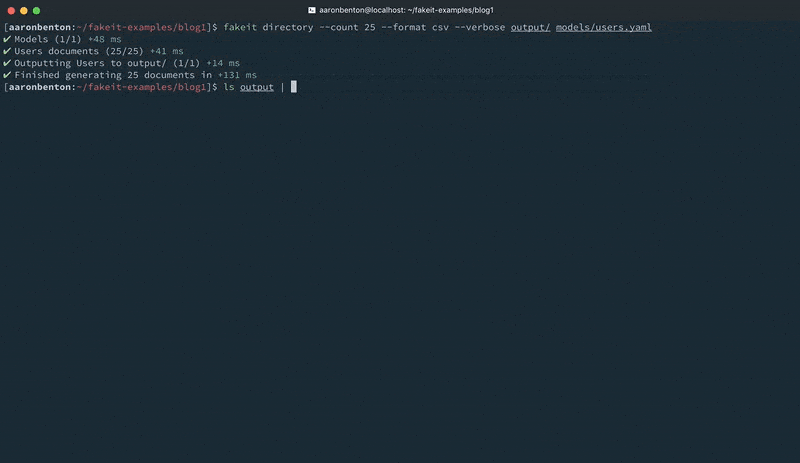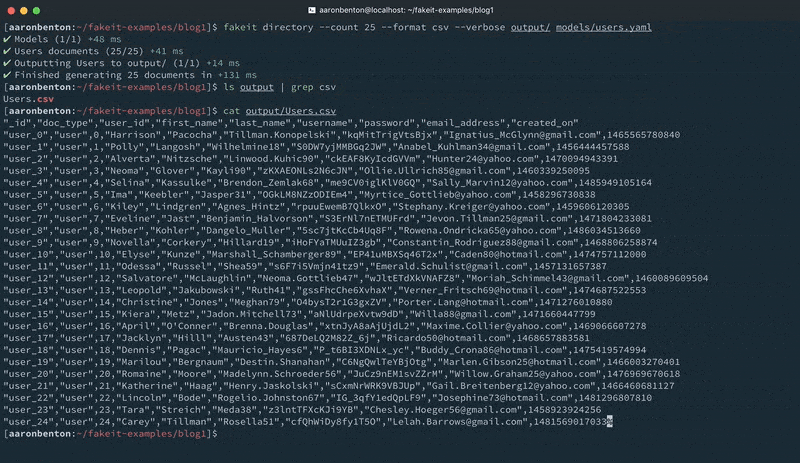
fakeit directory –count 25 –format csv –verbose output/ models/users.yaml |
This will create a single CSV file whose name is the name of the model, in this case name: Users with the resulting file being named Users.csv
Whether you are using JSON files, Zip Archives or CSV files all of these can be imported into Couchbase Server by using the CLI tools cbdocloader (for *.json and *.zip files) or cbimport (for *.json and *.csv files)
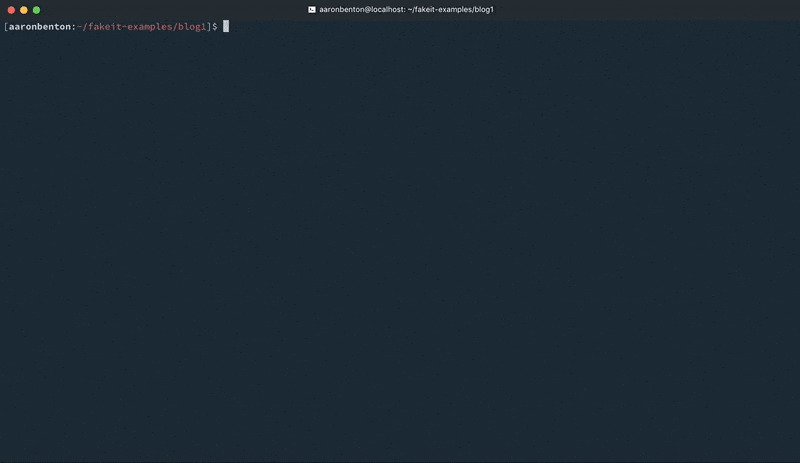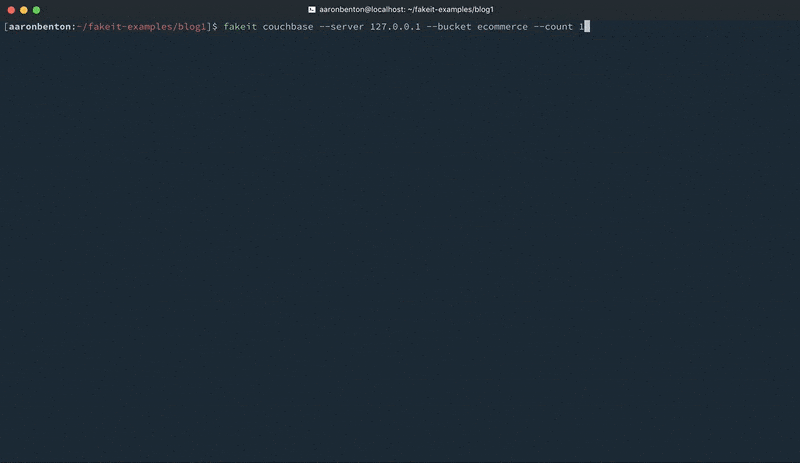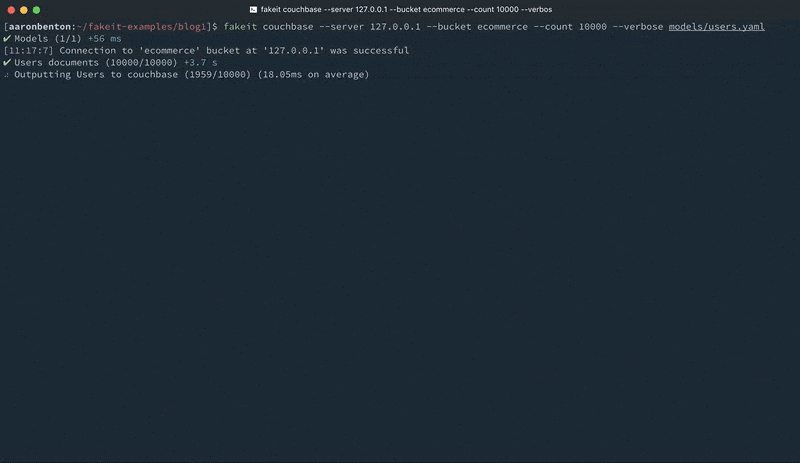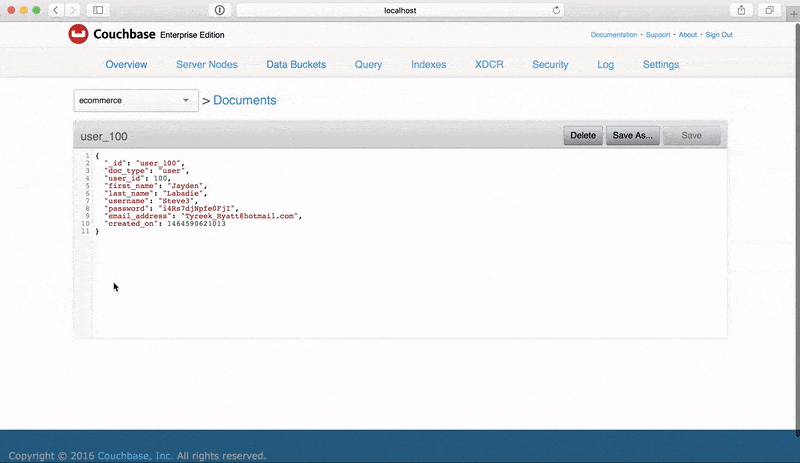
While generating static files is beneficial, there is still the extra step of having to import them into Couchbase Server through the available CLI tools. FakeIt also supports Couchbase Server and Sync Gateway as output destinations. We can generate 10,000 JSON documents from our users.yaml model, and output them to a bucket named ecommerce on a Couchbase Server running locally using the command:
|
1 |
fakeit couchbase –server 127.0.0.1 –bucket ecommerce –count 10000 –verbose models/users.yaml |
Conclusion
We’ve seen how we can represent a user’s JSON model using YAML to document and describe how a properties value should be generated. That single users.yaml file can be output to the console, JSON files, Zip archive of JSON files, CSV files, and even directly into Couchbase. FakeIt is a fantastic tool to speed up your development and generate larger development datasets. You can save your FakeIt models as part of your codebase for easy repeatable datasets by any developer.
FakeIt is a tool to ease development and testing of your Couchbase deployment. While it can generate large amounts of data, it is not a true load testing tool. There are CLI tools available for load testing and sizing such as cbc-pillowfight and cbworkloadgen
Up Next
- FakeIt Series 2 of 5: Shared Data and Dependencies
- FakeIt Series 3 of 5: Lean Models through Definitions
- FakeIt Series 4 of 5: Working with Existing Data
- FakeIt Series 5 of 5: Rapid Mobile Development w/ Sync-Gateway

This post is part of the Couchbase Community Writing Program
[…] FakeIt Series 1 of 5: Generating Fake Data we learned that FakeIt can generate a large amount of random data based off a single YAML file and […]
[…] far in our FakeIt series we’ve seen how we can Generate Fake Data, Share Data and Dependencies, and use Definitions for smaller models. Today we are going to look […]
[…] FakeIt Series 1 of 5: Generating Fake Data […]
On Couchbase 5.0 and above, you need to specify a username and password for Couchbase.
You can do it by adding the parameters –username (or -u) and –password (or -p) to the “fakeit couchbase” command