



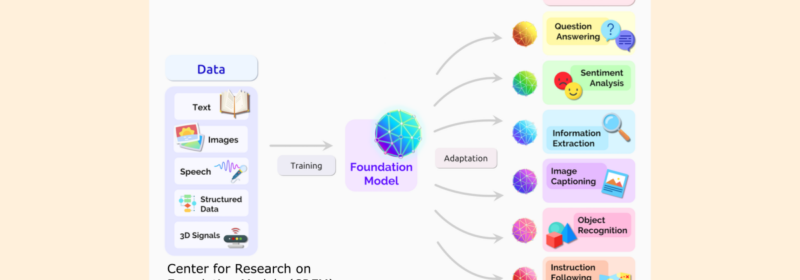
What are Foundation Models? (Plus Types and Use Cases)
What is a Foundation Model? A foundation model is a powerful type of artificial intelligence (AI) trained on massive amounts of general data, allowing it to tackle a broad range of tasks. Foundation models, such as OpenAI’s GPT (Generative Pre-trained...

SAML Integration Simplified: Connecting Microsoft Entra with Couchbase Server for Secure SSO
In today’s digital landscape, businesses are continuously seeking efficient ways to manage their access control and authentication processes. Integrating Microsoft Entra (formerly known as Azure AD) with Couchbase Server offers a robust and secure solution for single sign-on (SSO) using...
Istvan Orban April 26, 2024

Chat With Couchbase Technical Documentation
Couchbase community: Meet the Couchbase Docs chatbot, your new Generative AI-powered documentation assistant. Now available on the docs.couchbase.com website, the new chatbot will transform the way you learn about Couchbase products. It’s like having a Couchbase expert that’s always on...
A Guide to Serverless Functions
Serverless functions have become a popular application development and deployment approach. By abstracting infrastructure management and embracing event-driven architecture, they offer a flexible solution for developers. The main goal of serverless is to eliminate the need for infrastructure management and...
Couchbase Product Marketing April 19, 2024
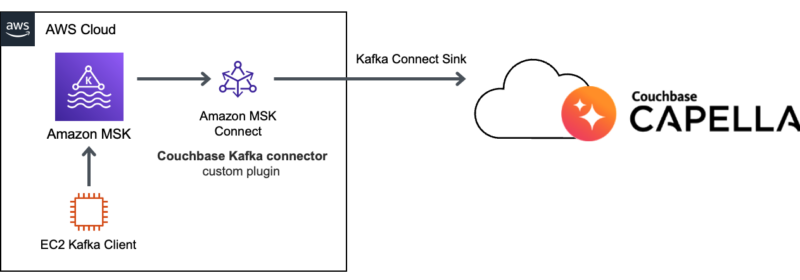
Streaming Data with Amazon MSK and Couchbase Capella
We see that a significant number of customers take advantage of Couchbase integration with Apache Kafka, by using Couchbase Kafka connector plugin that provides you capability to reliably stream data to and from Apache Kafka at scale. Apache Kafka is...
Saurabh Shabhag, Partner Solutions Architect, AWS April 17, 2024

Getting Ready for SAML: Essential Preparations for Couchbase Server Integration
In the evolving landscape of digital security, the integration of Couchbase with a Security Assertion Markup Language (SAML) Identity Provider (IdP) stands as a cornerstone for robust authentication mechanisms. Why Should You Implement SSO with Couchbase Server? Single Sign-On (SSO)...
Istvan Orban April 17, 2024

Migrate From MongoDB to Couchbase in Minutes With the CLI and IDE Plugins
Trying Couchbase just got even easier, you can now import your MongoDB data and indexes into Couchbase seamlessly. Whether you prefer working directly from the command line, or within your favorite IDE, our various new offerings—cbmigrate CLI, Couchbase VSCode Extension,...

Join Us at DevNexus 2024 – Atlanta
Are you ready for the longest running and largest Java Ecosystem Conference in the world? We are so excited to see you at DevNexus 2024! Hosted in Atlanta, April 9-11, you will find 3 days, 6 full-day workshops, 14 tracks,...
Nyah Macklin - Developer Evangelist April 10, 2024

Embracing AI From Cloud to Edge With Google Distributed Cloud and Couchbase
Unveiled this week at Google Cloud Next, our longtime trusted partner Google announced the Google Cloud Ready Distributed Cloud program. The new program is designed to validate partner solutions on Google Distributed Cloud (GDC), Google’s AI-ready modern infrastructure that customers...
Mark Gamble, Dir Product & Solutions Mktg, Couchbase April 9, 2024

Couchbase Server 7.6 Awesomeness Unleashed: The Top 10 Features Every SRE Must Know!
Hey SRE Champions! Couchbase has just dropped a game-changing update, and we’re here to immerse you in real-world stories that highlight the top 10 features turning System Administrators, DevOps and Site Reliability Engineers (SREs) into superheroes. Join us for a...
Chris Malarky April 8, 2024

Improved Debuggability for SQL++ User-Defined Functions
User-defined functions (UDFs) are a very useful feature supported in SQL++. Couchbase 7.6 introduces improvements that allow for more debuggability and visibility into UDF execution. This blog will explore two new features in Couchbase 7.6 in the world of UDFs. Profiling...
Dhanya Gowrish, Software Engineer April 5, 2024

5 Cool Things I Learned in My First Month at Couchbase
Starting a new job is always a little bit nerve wracking. Will I fit in? Will my coworkers like me? What is the culture like? I don’t think this feeling ever goes away no matter if you are new in...
Caroline Kerns April 4, 2024