
Despite similar names, Couchbase Server and Apache CouchDB are quite different systems.


Here’s a quick overview of how they differ and what they have in common. We're comparing Couchbase 4.1 and Apache CouchDB 1.6 and we'll post again when CouchDB 2.0 is released.
Quick overview
|
Couchbase Server |
Apache CouchDB |
|
|
Data models |
Document, Key-Value |
Document |
|
Storage |
Append-only B-Tree |
Append-only B-Tree |
|
Consistency |
Strong |
Eventual |
|
Topology |
Distributed |
Replicated |
|
Replication |
Master-Master |
Master-Master |
|
Automatic failover |
Yes |
No |
|
Integrated cache |
Yes |
No |
|
Memcached compatible |
Yes |
No |
|
Locking |
Optimistic & Pessimistic |
Optimistic with MVCC |
|
MapReduce (Views) |
Yes |
Yes |
|
Query language |
Yes, N1QL (SQL for JSON) |
No |
|
Secondary indexes |
Yes |
Yes |
|
Notifications |
Yes, Database Change Protocol |
Yes, Changes Feeds |
Data model
Couchbase Server
Couchbase Server is both a key-value store and a document store, meaning that you can store binary or any other kind of data using Couchbase Server, as well as JSON documents.
Couchbase Server uses the memcached binary protocol for key-value operations and REST APIs for N1QL and view queries.
Apache CouchDB
Apache CouchDB stores JSON as documents, with the option of attaching non-JSON files to those documents.
CouchDB uses a REST API to write and query data.
Query
Couchbase Server
Couchbase Server provides three ways to query the data it stores:
- N1QL: a SQL-like query language for JSON.
- Views, including multi-dimensional: much like CouchDB views.
- Key-value look-ups.
If you know the key of the document you need, you can perform a simple GET request using that key. There’s no need to create any additional indexes.
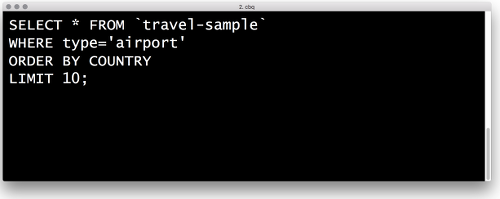
For more involved query, you can use N1QL. N1QL provides a familiar SQL-like way to query JSON data. For example, to find a user profile based on that user’s email address, we use the following N1QL query:
|
1 |
SELECT * FROM `users` WHERE email=”matthew@couchbase.com” AND WHERE type=”userProfile”; |
N1QL allows you to query JSON with the same flexibility you’d expect from a relational database, including JOINs across documents.
You can also create views that work in a similar way to those you’ll find in CouchDB. These are especially useful for multidimensional queries, such as working with geospatial data.
Apache CouchDB
As a pure document store, Apache CouchDB allows you to retrieve data based on the contents of documents. It does this through a system of views. You can also pull out a full document using its key.
You can think of CouchDB’s views as indexes that you generate by writing JavaScript Map/Reduce queries. For example, if you want to retrieve a user profile based on that user’s email address you could:
- Create a view that provides all the documents that contain an email address and have a type of ‘userProfie’.
- Query that view for the email address of the user whose profile you want to retrieve.
Architecture
Couchbase Server
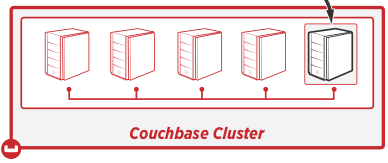
Couchbase Server is built from the ground-up to operate as a cluster of nodes.
Each server in the cluster takes responsibility for a portion of that hash space. On the application server, the Couchbase client library holds a map that shows which IP addresses are responsible for which parts of the hash space. The location of each document is decided by running a hash on the document’s bucket and key name and then placing it according to which server holds the relevant part of the hash space.
There is one active copy of each document. All writes are made to that active copy and, in normal operation, all reads come from it too. That means that there’s no need to worry about eventual consistency within a cluster as there are no writes to be replicated from elsewhere.
Replicas of each document are made automatically and are stored on a separate server from the active copy. With Couchbase Server, replication happens at the document level rather than the full server level. That means that each node has a different set of data and replicas are distributed right across the cluster.
There are no single points of failure and it’s easy to scale up to massive datasets by adding more servers to the cluster: the entire dataset doesn’t need to fit on every single server.
Caching
Couchbase Server has a built-in managed cache. For each request you make, Couchbase Server will transparently check the cache for the document you need. If you the document isn’t in the cache, it’ll load it from disk and then serve it to you.
All writes go into the cache and you can tune at which point in the request it is written to disk or replicated to other servers.
For your working set, most key-value requests are sub-millisecond.
Cross-datacentre replication
Couchbase Server can operate across availability zones and data centres. Each cluster operates independently, with changes replicated directly from server to server between the clusters.
This is ideal for disaster recovery and geographic load balancing.
Apache CouchDB
CouchDB servers operate as individual nodes that each contain a full copy of the data to be stored. Application servers can then read from and write to any of the CouchDB servers. Changes are then asynchronously replicated between each server, on a server-to-server basis.
One way to run a CouchDB cluster is to have a single master that accepts writes. Updates are then replicated to slaves and an HTTP load-balancer, such as nginx, to distribute reads evenly amongst those slaves.
This has two main consequences:
- the master is a single point of failure for accepting reads
- data read from the slaves is eventually consistent: there is a lag between a write happening on the master and that being replicated to all slaves.
Alternatively, a CouchDB cluster could accept writes to any node and then replicate between each. This would improve write availability but increase the scope for write conflicts, which CouchDB helps you detect, and the time it would take for all copies of the data to be in sync.
Development
Couchbase Server
Couchbase Server is actively developed by Couchbase Inc, with as an open source project. The clustering and distribution parts of Couchbase Server are written in Erlang, while data handling is written in C and C++. Some parts of Couchbase Server, such as N1QL, are written in Go.
Couchbase Server has several SDKs that are developed and supported by Couchbase Inc. These provide idiomatic access to the full range of Couchbase Server features, including N1QL, views and key-value access. Official SDKs are available for:
- Java (with additional support for Spring)
- .NET
- Node JS
- Go
- C/C++
- Python
- Ruby
- PHP.
Community-supported SDKs are available for other languages.
Couchbase Server works well with other systems, thanks to connectors developed and supported by Couchbase Inc. Connectors are available for:
- Spark
- Kafka
- Hadoop
- Elasticsearch
- Solr
- JDBC and ODBC, for N1QL.
Couchbase Server’s internal changes feed offers you an opportunity to roll your own connectors.
Apache CouchDB
CouchDB is written in Erlang, on top of the OTP framework, by a community of developers. Erlang is well suited to building fault tolerant systems.
CouchDB’s changes feed helps to integrate it with other systems.
Libraries that wrap CouchDB’s REST API are available from the CouchDB community.
License
Both Couchbase Server and Apache CouchDB are fully open source projects released under the Apache 2.0 licence.